
Important: Please note there is an updated version available!
Before proceeding, be aware that the following content is an older version of our OCR J277 Computer Science GCSE revision resources. We highly recommend checking out our latest and improved Cheat Sheets on the dedicated page for the most up-to-date and effective study materials.
To access the latest OCR J277 Computer Science GCSE revision resources and cheat sheets, click below:
Updated Cheat Sheets Page
Alternatively, you can open Paper 1 directly:
or Paper 2 directly:
J277 Paper 2 Cheat Sheet
Why upgrade to our latest Cheat Sheets?
🚀 Acclaimed revision material designed for optimal study efficiency.
🌟 Praised by students and educators for clarity, relevance, and effectiveness.
🧭 A curated selection of the most trusted and top-rated revision tools, saving you time and effort.
Say goodbye to outdated content and embrace our latest resources enhanced for clarity to ensure you get the best grades.
Click Here for the Updated Cheat Sheets!
Below is an old version for indexing purposes.

Ah yes computer science!
Cheat Sheet Changelog - Last recorded update to this one 21/05/2022 25:37
Firstly…
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License. I guess you could say it’s open source… see below…
By using this you are legally required to drop a thank you message in Baguette Brigaders. Click to join the Discord server!
READ ME PLEASE THANKS
Please use your class notes, if you have any, as well as this, to aid your revision. I’ve tried to make it as packed full of only the useful stuff which I think will come up in the exam. This covers 15 pages of specification content and 210 hours of lesson time, consolidated into one place, so might not cover everything in 100% detail, but I have written more for the things which people may find more confusing. If there are any errors then please let me know immediately. I have tried my best to make it as easy as possible to understand and get a grade 9😉
This cheat sheet covers all of specification for: J277/01: Computer systems, and J277/02: Computational thinking, algorithms and programming
From OCR:
J277/01: This component will assess:
• 1.1 Systems architecture
• 1.2 Memory and storage
• 1.3 Computer networks, connections and protocols
• 1.4 Network security
• 1.5 Systems software
• 1.6 Ethical, legal, cultural and environmental impacts of digital technology
ABOUT ME
For ease of access, I’ve written this in a way designed to be read smoothly across any device, called Markdown. It’s easy to navigate and should look nice to read. To skip to areas you are weak on, I’d recommend using the side bar on the left - you may need to open in desktop site or read on a computer to quickly skip between parts.
Anyway, without waiting much longer, let’s start with…
Paper 1
1.1 - Systems architecture
1.1.1 Architecture of the CPU
Advance information: The purpose of the CPU, common CPU components and their features, and Von Neumann architecture will be directly assessed.
The purpose of the CPU - the F-D-E cycle
The Fetch-Decode-Execute cycle is the main job of the CPU. To execute a program, the program code is copied from secondary storage into the main memory. The CPU’s program counter is set to the memory location where the first instruction in the program has been stored, and execution begins.
In a program, each machine code instruction takes up a slot in the main memory. These memory locations each have a unique memory address. The program counter stores the address of each instruction and tells the CPU in what order they should be executed.
Step by step:
- The CPU checks the program counter to see the next instruction to execute.
- The program counter gives a memory address to where the next instruction is
- The CPU fetches the instruction from this memory address
- The instruction is decoded and executed. For example the value decoded could be a number, which is entered to the ALU (arithmetic logic unit) and added to another fetched from cache and multiplied.
- The program counter increments by 1
- The cycle is repeated indefinitely
CPU components and their function(s)
The ALU (arithmetic logic unit)
- Performs calculations and logical operations
- Where decisions are made (e.g
if x > 10)
The CU (control unit)
- Fetches, decodes and executes instructions
- Controlls hardware
Cache
- A small amount of high speed memory physically inside the CPU.
- Temporarily holds small amounts of data which the CPU will reuse often.
- Speeds up the system - does not have to wait for some data in memory to be fetched
- Level 1, 2, 3 cache - 1 is the fastest, most expensive, has the lowest amount of storage, likewise 3 is the slowest, least expensive but contains the most amount of potential storage
Registers
- What Ethan Skipper is on
- Small amounts of high speed memory in the CPU used to store small amounts of data needed for processing
- Includes the address of the current instruction, the next instruction to be executed, and the results of calculations
In case you find the difference between Cache and Registers difficult, here’s something useful from Stack Overflow:
- CPU register is just a small amount of data storage, that facilitates
some CPU operations. - CPU cache, is a high speed volatile memory which
is bigger in size, that helps the processor to reduce the memory
operations. - It is not very inaccurate to think of the processor’s
register as the level 0 cache, smaller and faster than the other
layers of cache in-between the processor and memory. The difference
is only that from the point of view of the instruction set, cache
access is transparent (the cache is accessed through a memory address
that happens to be a cached address at the moment) whereas registers
are explicitly referenced in each instruction.
There will probably be a table to tick what things do, or a 2-4 marker asking what something does and to explain it. I’d recommend learning 2 registers in detail, and what 4 just do.
Von Neumann architecture
This is basically a summary of the above.
Von Neumann architecture is the design of which most every computer now is comprised of. It states:
- Data and instructions are stored as binary
- Data and instructions are both stored in primary storage
- Instructions are fetched from memory one at a time and in order
- The processor decodes and executes an instruction, and then does the same for the next instruction
- This will continue until there are no more instructions
A processor based on von Neumann architecture has five registers which it uses for processing:
- the program counter (PC) holds the memory address of the next instruction to be fetched from primary storage
- the memory address register (MAR) holds the address of the current instruction that is to be fetched from memory, or the address in memory to which data is to be transferred
- the memory data register (MDR) holds the contents found at the address held in the MAR, or data which is to be transferred to primary storage
- the current instruction register (CIR) holds the instruction that is currently being decoded and executed
- the accumulator (ACC) is a special purpose register and is used by the arithmetic logic unit (ALU) to hold the data being processed and the results of its calculations
Note the above was heavily taken from Bitesize as it’s just easier to explain
Personally I find this the easiest way to remember them:
- program counter counts the programs by 1 every cycle
- memory address register has the current memory address
- memory data register has the memory data at the address
- don’t worry about the CIR because it’s self-explanatory
- accumulator (ACC) holds data being processed and the results of it
1.1.2 - CPU performance
Clock speed
The clock speed is measured in gigahertz (GHz) and represents how many fetch-decode-execute cycles happen per second. 1 GHz = 1 billion cycles.

^^ My computer running at 4.27 GHz, overclocked from 3.7 GHz. This means that 4,270,000,000 fetch-decode-execute cycles are happening per second. Speedy, right?
A clock speed of 4.27 GHz means that 1 clock happens 274,000,000 times faster than a reflex action. In that time, light itself can only travel about 8cm. In other words, they’re really fast.
However, a CPU which cannot keep up with its clock will corrupt its data. A very fast clock speed will cause the CPU to overheat and thermal throttle, reducing its performance to stop it melting…
Cache size
Transferring data in and out of memory takes much, much longer than from cache. Therefore, by placing frequently accessed data on cache, it results in everything using that function (such as square roots) being executed much faster. The more cache there is, the more data can be stored closer to the CPU.
Cache is ‘graded’ at different levels depending on its speed. L1 is usually part of the CPU chip and is both the smallest and the fastest to access. Its size is often restricted to between 8 KB and 64 KB. L2 and L3 caches are bigger than L1. They are extra caches built between the CPU and the RAM. Sometimes L2 is built into the CPU with L1.
L2 and L3 caches take slightly longer to access than L1. Each CPU core has its own set of L1 cache, but they can share higher levels.
However, cache is very expensive (L1 costs ~£1 per kilobyte) and is limited by the space of the CPU die, and is very small, so cannot be a full replacement of memory.
Core count
A CPU has multiple cores on it. CPUs with multiple cores have more power to run multiple programs at the same time.
However, doubling cores does not double clock speed. Some headroom is needed to communicate between each core.
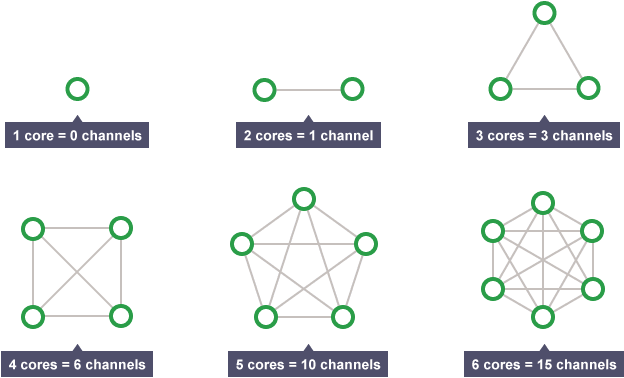
Something you don’t need to remember, I don’t really know why I put it here. Just remember more cores = faster as it can do multiple tasks concurrently!
1.1.3 - Embedded systems
An embedded system is a a small computer inside of a larger system. PCs would be categorized as general purpose systems, as they can do pretty much anything. Embedded systems on the other hand have one specific function which they run.
General process computers are designed to access the Internet, play games, play videos, write programs. These all require applications to run. Tablets, phones and consoles are now more classed as general process as they now can run several applications.
Examples of embedded systems include GPS systems, digital watches and fitness trackers.
They are not reprogrammable either - all the programming is done in manufacturing.
Advantages of these systems include they require less power to run and are cheaper to make as their processors are not as powerful.
1.2 Memory and Storage
Advance information: All below will be assessed.
1.2.1 Primary storage
Primary storage consists of RAM (random access memory) and ROM (read only memory). ROM is non-volatile (retains its data after being powered off) and is usually often now only used to boot the computer, providing for the BIOS or UEFI.
Memory/RAM is small in size compared to secondary storage, but is much faster as it does not have moving parts or have to retain that information. It is usually from 4-16GB in size. The more RAM a computer has, the more programs and instructions it can store simultaneously.
Virtual memory is needed in systems. Virtual memory is a area of secondary storage which is used as an overflow for when memory is filled up. When RAM is full, data which would have gone to memory goes to an area of the disk drive. However, virtual memory is much slower than even the fastest SSDs, let alone HDDs with their moving parts.
1.2.2 Secondary storage
Secondary storage is non-volatile, meaning it retains the data written to it even when offline.
A HDD (magnetic) has high capacity and involves flipping magnetic polarity to store bits. It is fairly fast to access. A SSD (solid state) has high capacity and involves trapping electrons to store bits. They are extremely fast to access. A USB drive (solid state) is tiny in comparison but very portable so is useful for transferring files between people and their computers. Optical storage devices like CDs and DVDs use a laser to scan the tracks, and when light reflects back it will either reflect from ‘lands’ - representing 1, or does not reflect in ‘pits’ - representing 0.
Embedded systems may not need these as the instructions to run them are usually in ROM. For example, a watch does not need to edit the time as it runs all the time.
1.2.3 Units
The basic unit is the bit. It represents 1 or 0. Above this is the nibble - or 4 bits. Above this again is the byte, or 8 bits.
A kilobyte is 1000 bits.
A megabyte is 1000 kilobytes. (1,000,000 bits)
A gigabyte is 1000 megabytes. (1,000,000,000 bits)
A terabyte is 1000 gigabytes. (1,000,000,000,000 bits)
An image is usually be 500kb. Therefore, on a 2GB USB stick, 2000 images.
Videos can be 100 megabytes, so 20 image can be stored.
Sound file size = sample rate x duration (s) x bit depth
Image file size = colour depth x image height (px) x image width (px)
Text file size = bits per character x number of characters
1.2.4 Data storage
Advance information: All below will be assessed.

There’s a lot in this topic (including the things I find the hardest but shh)
Denary to binary
To convert a denary number into binary, write out all the base 2 numbers in a row (128, 64, 32, 16, 8, 4, 2, 1). Then, get your number, let’s say 253, and subtract it from the largest. You’d then get 125. Write ‘1’ below the ‘128’ and repeat on the next numbers. If when you subtract it it’s negative, write a zero below and then do the next smallest number.
Adding binary digits
0 + 0 = 0
0 + 1 = 1
1 + 1 = 0, carry 1
1 + 1 + carried 1 = 1, carry 1
Denary/binary to hex
Hex(adecimal) is a base 16 system to simplify binary representation. A hex digit can be any of these: 0 1 2 3 4 5 6 7 8 9 A B C D E F.
Each hex digit represents a 4 digit binary sequence.
0 in hex is 0 in denary, and 0000 in binary.
Remember how to convert denary to binary? Well, firstly convert the denary into binary, then split the 8-bit digit binary number into nibbles of 4 bits each. Then, add 1 to 0000 (binary) whilst incrementing hexadecimal by 1. Let’s go through an example.
- Convert 103 into hexadecimal. [2 marks]
- Convert 103 into binary.
= 01100111 - Split into nibbles
= 0110 0111 - Work out hex of nibble 1
= 6 - Work out hex of nibble 2
= 7 - Put together
= 67
The other way is to divide the denary number by 16 until you can’t (here, 6 times). Then get the remainder (here, 7). Then put together. Magic ✨
- Convert 212 into hexadecimal. [2 marks]
Try and work it out. The answer is below ‘Binary shifts’ below…

I guarantee you this will be on my test lol
Hex to denary/binary
You can reverse the above. Personally, I’d write down the hex digits, and convert them into nibbles where I can then easily convert into denary.
Binary shifts
A shift of 1 to the left means multiply by 2.
A shift of 3 to the left means multiply by 2^3 = 8
A shift of 1 to the right means divide by 2
A shift of 3 to the right means divide by 2^3 = 8
left = multiply, right = divide.
Answer to 2) Convert 212 into hexadecimal. [2 marks]
- to binary = 11010100
- nibbles = 1101 0100
- nibble 1 = D (remember it goes into ABCDEF)
- nibble 2 = 4
- answer = D4
Characters
Characters are also represented as binary. In ASCII, there are 8 bits, so that’s 255 characters possible. In Unicode, there are 16 bits, or more, allowing it so represent every character and emoji in the world - over 2 million.
A in binary is 0100 0001.
Character sets are ordered logically, so B is one more than A:
B in binary is 0100 0010.
Images
An image is represented as a series of pixels, again, represented as binary. Each pixel has a specific colour, represented by a specific code (can be a hex value).
The image’s size and quality can be affected by the colour depth and resolution.
A black and white image has a bit depth of 1. This means it can only represent two colours - 21 = 2 colours. An image which uses 10 bit depth can represent 210 = 1024 colours. Colour depth = range of colours available.
Colour depth is interchangable with bit depth.
Size, or dimensions, is how many pixels the image contains, in terms of height by width. 1920x1080 is a classic example - a screen with these dimensions would have 2,073,600 pixels.
The size of an image file can be estimated using:
- the image height in pixels
- the image width in pixels
- the colour depth per pixel
If a 1920x1080 image, with a colour depth of 24 bits was to be saved:
1920x1080 = 2,073,600
2,073,600 x 24 = 49,766,400 bits
divided by 8 = 6,220,800 bytes
divided by 1000 = 6220.8KB / 6.2208 MB
Resolution is used to describe how densely packed the pixels are. A high resolution would have more pixels, but will be larger in size. A low resolution image will look like Minecraft when enlarged, but has a low file size.
Files contain extra data called metadata. Metadata includes data about the file itself, such as file type, date created, author, geolocation and camera.
An image file also includes metadata about the image data itself, such as the height and width of the image, the resolution and the colour depth
Sound
Sample rate is the number of samples recorded in a second. It is measured in hertz. The higher the sample rate, the closer the recorded digital signal is to the original, analogue sound. AN audio file is usually recorded at 44.1KHz which is a compromise between low file size and high quality. (All my videos are rendered at 96KHz for the best quality 😉)
Bit depth is the number of bits used to record each sample. The higher the bit depth, the more accurately the sound can be recorded but the higher the file size.
Bit rate is the amount of data processed per second. It is calculated by sample rate x bit depth, and is in bits per second. Higher bit rate = higher quality sound, and also the file size.
1.2.5 Compression
There are 2 types of compression.
Lossy compression
Lossy - some data is removed, reducing the overall data and quality and therefore size of the file. In an image, this can be seen through reducing colour depth, reducing the amount of colours in the image, reducing the file. Bit depth can be reduced in audio files to reduce the file. > Remember, in bit depth, it squares every time. A bit depth of 4 would mean 2^4 bits, or 16 potential colours or audio bits.
Examples of lossy compression include JPEG, MPEG (or MP4) and MP3 files.
Lossless compression
For other files, data cannot be lost, like texts. Files need to be reduced in size without the loss of data. WAV audio files or PNG image files are examples of lossless formats. However, lossless files are bigger than lossy, even when compressed.
For example, a binary representation of 000000111100110000000111111 can be represented as 604121217161. (because there’s 6 zeroes, 4 ones, 2 zeroes etc)
This would reduce the file from 27 bytes to 12 bytes. A reduction of over 60%!
1.3 Networks, connections and protocols
Advance information: The following will be directly assessed:
- Factors that affect the performance of networks
- The hardware needed to connect stand-alone computers into a Local Area Network
- The Internet as a worldwide collection of computer networks.
1.3.1 Networks and topologies
A network’s topology is how different nodes (a device connected to a network) are arranged in it. All nodes are either wired or wirelessly connected.
Some useful key terms which you should probably know:
Router: directs and receives packets incoming/outgoing to/from the Internet to devices in a private network via IP addresses. It connects networks together - your home LAN to the Internet, or a WAN. Nodes connected to it are given private IP addresses (192.168.1.x) and has a public IP address. (This is what you see here)
Switch: A device which connects devices on a computer network by using packet switching to receive and forward data to the destination device. It uses MAC addresses to forward data at the data link layer. (MAC (Media Access Control) addresses are used to identify a device on the local network assigned by its Network Interface Card)
WAP: wireless access point. Usually built into the switch, or physically connected by wire to it. Unless there’s a repeater which would mean WAPs are connected to other WAPs
Packet switching: a method of breaking up data, and sending it using the most efficient route. For example, if you send an image, it will be broken up into ‘packets’ of around 1000 bytes each (if the image is 1mb then there’ll be 1000 packets) and then sent. To ensure data is not corrupted on route to the destination, each packet contains the following in a header: the IP address it is going to , the IP address it has come from, the sequence number of the packet, the number of packets in the whole communication, and error checking data
DNS: Domain Name System. How domain names are translated to IP addresses. When you go to ibaguette.com, your device will make a request to a DNS server asking for the actual IP address to connect to, such as 172.67.139.203. If a DNS server does not contain the IP address, your request will be forwarded to a bigger DNS server, and finally a root DNS server containing every single domain’s IP address.
The two topologies which you need to know are:
Star topologies
- Used in many networks
- Used by client-server networks - all data sent from clients pass through (a) central server(s).
- All computers can communicate to each other through the central switch.
Advantages include:
- If a node or its connection fails, other nodes can still communicate
- New nodes can be added by connecting it to the switch
- Any incoming data from the Internet cam be forwarded directly to the intended node.
- Fast data transfer to the hub as each wire isn’t shared with other computers
Disadvantages:
- The entire network will go down if the switch fails
- Can be expensive to set up - requires additional hardware such as the central switch and lots of network cables
They are used anywhere, from company buildings to your home right now. Your ‘router’ is currently acting as the switch, router and WAP for all the nodes connected in your house.
Mesh topologies
Full meshes are when every device is connected to every other device. Partial meshes are when every device is connected to at least another device, which shares a connection with other devices (the original device is indirectly connected with every other device)
Advantages:
- No single point of failure – resilient to attacks
- Messages can be received more quickly if the route to the intended recipient is short
- Expansion and modification can be done without disrupting the network
- Data can be transmitted from different devices simultaneously
Disadvantages:
- Can involve redundant connections
- Expensive to install cabling if using wired connections
- Network maintenance and administration is difficult
- Full mesh networks are impractical to set up because of the high number of connections needed
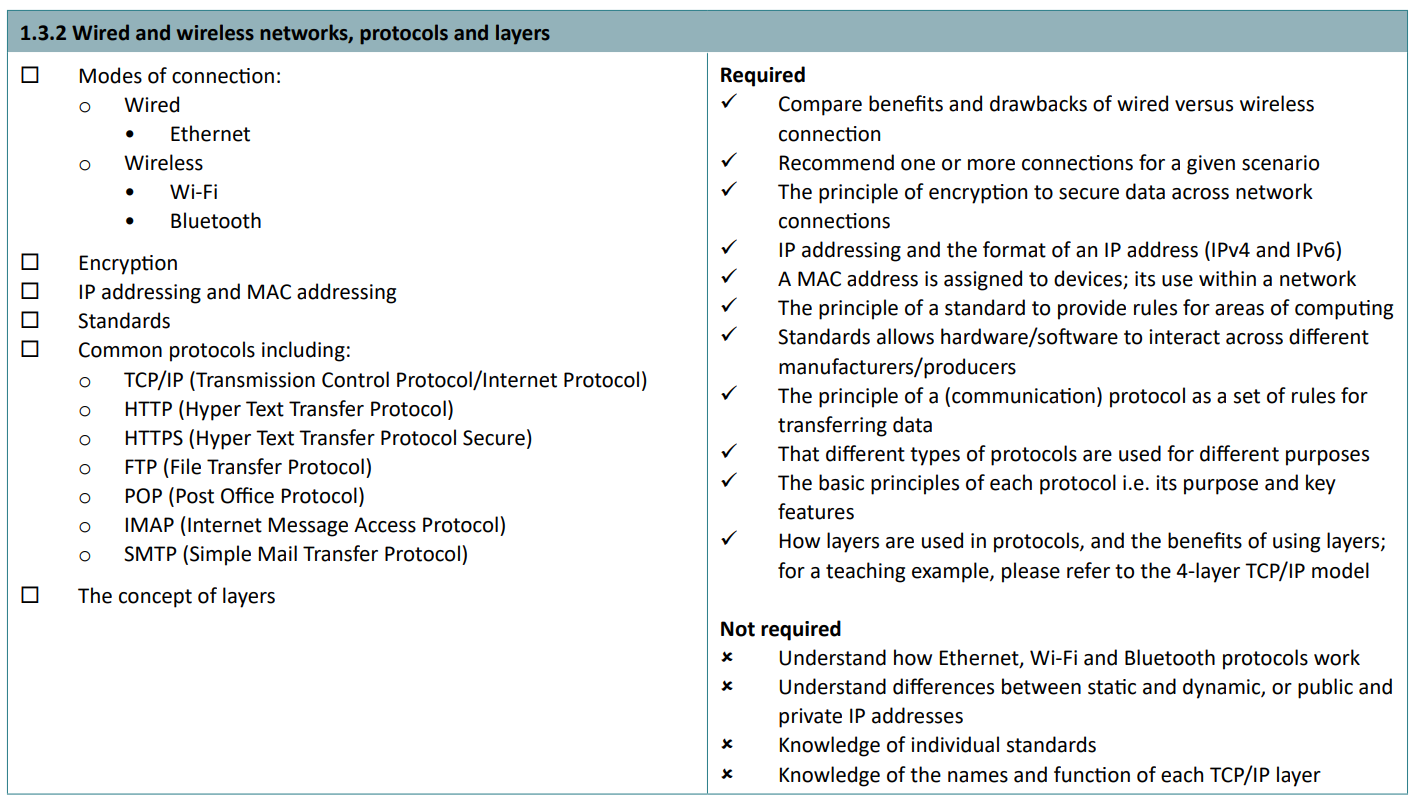
1.3.2 Wired/wireless, protocols, networks
Advance information: The following will be directly assessed:
- Modes of connection
- Encryption
- IP addressing and MAC addressing
- Standards
- Common protocols
A network is a group of two or more computers connected together to communicate. There are 2 ways for them to communicate: wired (ethernet) and wireless (Wi-Fi, Bluetooth).
It may seem obvious but benefits for being in a network include accessing and sharing resources, sharing hardware like printers, communications via email, text or video, and roaming profile (can access your files from any computer in network).
In larger networks, antiviruses and firewalls can be implemented network-wide instead of on individual computers, improving security and cost effectiveness.
Admins can monitor what people do on these networks, and give them rights (User Access Levels) to restrict access. However, networks can cost a lot as equipment like dedicated cables or switches are needed to communicate, and malware can spread more quickly if a network has poor security.
IP and MAC addressing, standards
The 32-bit IP address system is also known as IPv4. It allows for over 4 billion addresses (2^32 = 4,294,967,296 addresses). We’re running out very quickly.
IPv4 addresses are just numbers, like
248.228.179.104. Each number separated by decimals cannot be over 255, as that’s the 8 bit limit.
IPv6’s adoption is increasing now. IPv6 uses 16 bits for each section of the address, creating a 128-bit address. This allows almost 80 octillion unique IP addresses.
IPv6 addresses can be letters as well. They are separated by colons, such as
8cfb:3abd:dde5:ca41:e080:0328:6e86:5007. Each part separated by colons can be from 0000 to ffff. This means that there are 1,028x more addresses than IPv4. That’s 340,282,366,920,938,463,463,374,607,431,768,211,456 addresses.
(no, you don’t need to remember that)
A MAC address is different to an IP address - it is assigned to devices within a network. It can’t be changed by the user, as it’s on the network card on the device.
Remember, a protocol is a set of rules that governs the transmission of data. For example, HTTPS.
Standards allows hardware/software to interact across different manufacturers/producers. For example, HDMI or USB-C (love you Apple)
Encryption
Encryption is the process of changing a message so that it can only be understood by the intended recipient, through the use of a public and a private key (also known as asymmetric encryption). A public key can be given to anyone - it can be used to encrypt a message. but it cannot decrypt a message - only the second key (the private key) can do that. The message will remain encrypted unless the private key is compromised, either by giving it out or by brute forcing it.
Unencrypted messages are referred to as plaintext messages. Encrypted messages are known as ciphertext.
https://www.bbc.co.uk/bitesize/guides/zr3yb82/revision/4
Common protocols
You need to know a few common protocols.
- TCP/IP (Transmission Control Protocol/Internet Protocol)
- Used for accessing the Internet. Set of rules describing how packets are sent. All packets have source IP, destination IP, packet reassembly sequence, the actual data (or payload), and error checking details.
- HTTP (Hyper Text Transfer Protocol)
- Sends web pages from the webserver to your browser.
- HTTPS (Hyper Text Transfer Protocol Secure)
- Sends web pages securely encrypted from the webserver to your browser. Needed on sites with private information like banks.
- FTP (File Transfer Protocol)
- Transfer files. You can upload a file to a FTP server and someone else can download it.
- POP (Post Office Protocol)
- Used to download email to device, then deletes from server.
- IMAP (Internet Message Access Protocol)
- Used to download email from the server, but caching it on-device. Doesn’t delete from web server.
- SMTP (Simple Mail Transfer Protocol)
- Used to send the email
Layers
Finally, you need to know how layers are used in protocols, and the benefits of using layers; for a teaching example, please refer to the 4-layer TCP/IP model.
Not requires: Knowledge of the names and function of each TCP/IP layer
Layering means the breakdown of the sending of messages into separate components and activities, with each component handling a different part of communication. Therefore, it allows standards to be put in place and simply adapted as new hardware and software is developed.
See this Bitesize page if you want to learn more, but it’s not required
- Application layer - applications and protocols.
- Transport layer - breakdown into packets
- Network layer - adds sender and receiver’s IP addresses to packets and sends over network
- Data link layer - the NIC and drivers are here and send it to another computer
1.4 Network security
1.4.1 Threats to computer systems

Malware
Umbrella term for malicious software designed to compromise a system.
Viruses - often in another file. When ran, they replicate and can spread throughout a network. They usually delete or modify other data, including personal documents or critical system files. Can upload your files to a server.
Worms - the same as viruses but are not hidden - often distributed through emails
Trojans - a malicious application pretending to be a useful application. A user must run it to spread.
Spyware - monitor a user’s activities and sends them back to a server. This could include websites visited, passwords, usernames and applications opened
Adware is the same as this but used to serve more relevant ads to a user. Very common on mobile devices. My dad even had some adware on his iPhone lol. Safari (even private) bad for privacy.
Ransomware - arguably the worst type of malware. Encrypt documents, and require a ransom payment, usually Bitcoins, to decrypt the data. Often will delete data after a certain time if not paid. Often won’t decrypt the data even if paid. Usually deletes copies of data and locks the system by taking over how the system boots. Very easily spreads through the network if ran as administrator. (user access levels useful here!)
Social engineering
e.g. phishing, people as the ‘weak point’
Emails which try to deceive users to give their personal details. Designed to look like a genuine email from a useful service, like a bank, and will have a link to a website (still looking like a real bank) where there will be a username/password field, and maybe even credit card numbers. Of course, when you enter the data, it’s just sent to someone else.
Brute-force attacks
A program is used to systematically try all possible combinations of a username and password until the correct one is ‘cracked’.
Denial of service attacks
Where a computer sends loads of requests to a server to overwhelm it. The server will become overwhelmed and legitimate requests will no longer work.
Multiple computers doing this concurrently is called a distributed denial of service attack, or DDoS. They usually only last a few seconds but send tens of millions of requests.
Data interception and theft
Data interception is when data is intercepted while being transferred, using a special software called a ‘packet sniffer’. It can identify what packets are doing and their destination across the Internet or in a network. They are usually difficult to detect, as the data still reaches its intended destination. The information gathered is sent back to a server where it can be seen by malicious entities.
SQL injection
You don’t need to know what SQL actually is, but rather the process of it. SQL is widely used in databases to ensure their structures are maintained and to quickly read a value in it. SQL code can be entered as a data input in, for example a username/password field, which can cause errors. Even worse, someone can input something like FROM * PRINT Passwords to get a list of everyone’s passwords if unencrypted!
1.4.2 Preventing vulnerabilities
Advance information: ‘Common prevention methods’ will be assessed.
Penetration testing
Pen testing is when authorised users (including white hat hackers) probe a network for weaknesses, and attempt to exploit them. It is used to check how resistant a network is against malicious attacks by trying to identify security issues before they are exploited. White hat hackers or organisations who attempt to find vulnerabilities can get paid hundreds of thousands for finding issues!
Anti-malware software
Anti malware detects installed malware, prevents malware from being installed and removes malware from a device. It scans through all files that are run or modified and sees if it matches a list of known malicious files. However, if the antimalware software is not updated, it may not be able to correctly identify new, zero-day threats which the system is exposed to.
Firewalls
Firewalls monitor traffic and allow it to pass through or deny it. It can be placed in front of the network, or can be placed in front of an individual device. Legitimate programs such as a game server requires the firewall to allow a program or port (e.g for a Minecraft Java server the port is 25565) to communicate with other devices. Firewalls can be hardware or software based, and as most things hardware-based firewalls are more effective but cost more than software-based implementations.
User access levels
User access levels only allow a user to do certain things, including running software, accessing the Internet, installing new software and editing the accounts of other users. In a school, students will be denied the access to managing other students and software, but will be allowed to access the Internet. Teachers will be allowed to manage students, and maybe the software installed. Finally, admins will be able to access everything.
This reduces the risks as if a student downloads a virus, it will not be able to access any other device, as it is effectively isolated from managing network devices. However, if an admin gets infected, it would mean disaster for the network…
Passwords
Passwords are used to verify a user’s identity. Secure passwords could include a password policy to ensure it is secure and difficult to guess, and one changes regularly. They should ideally be unique across different websites, so if one website account is compromised, the same passwords cannot be used to login to your account on another site which you might want to be kept secure, like a bank.
Encryption
The process of changing data from plaintext to cyphertext so it cannot be understood. For example if a database containing passwords gets accessed by a hacker, the passwords themselves are not visible and the user’s private key is still needed to decrypt them. Smart, right?
Physical security
Server rooms should be locked and only authorised people such as the admins can unlock them. Obviously, if someone gets into a server room, they can nick all the drives containing users’ information. Also, don’t write down your passwords on a sticky note, someone can just take a picture of them…
1.5 Systems Software
1.5.1 Operating systems

An operating system is a suite of programs that controls the general operation of a computer, and provides an easy way for us to interact with computers and run applications.
OSes can control hardware components, provide a UI, manage files in a file system, manage memory, manage users, and even provide multitasking. Examples are Windows and Linux in desktops, and iOS and Android for mobile devices.
User interfaces
UIs are (is a) program(s) that allow a user to interact with the computer. The GUI is the most popular as they include desktops and icons for ease of use, with menus and a mouse to interact with it. They are easy to use but use more processing power. CLIs are text based programs (command prompt in Windows) which are very powerful, and require little processing power to display due to their simplicity. However they are difficult for most people to use. Mobile UIs are basically the same as GUIs but replace the mouse with touch and gestures to navigate.
Multitasking & memory management
Multitasking is a classic example of OS’ evolution over the years. With CLIs a user could only do one process. Now, videos can be streamed while uploading documents to the cloud. This requires an OS to support it (duh) and enough memory to run multiple processes. The OS manages memory use to prioritise running processes, and when another process closes, this extra available memory gets allocated to the running program.
Peripherals and drivers
Peripherals are hardware devices physically connected to a computer like mice, monitors, printers, etc etc (you knew that right… RIGHT?!?)
OSes use drivers to control peripherals. Data is transferred between devices and the CPU, and this needs drivers to manage the interactions between the user and the computer. As drivers contain instructions on how to manage a device, every device connected will have its own associated driver. Any device can be used with a computer, as long as standards (wrote about above) are met and a driver is available. Drivers are frequently updated to improve the hardware device’s performance or to fix a bug.
However, if a driver update goes wrong then it will take some extra effort to fix it, as you can’t interact with the hardware with the bad driver…
User and file management
The OS controls…
… user management functions, e.g.:
- Creating, modifying, and deleting of an account
- Access rights (admin, or normal user)
- Logging actions
… handling files
- Create, modify and delete files
- Allocating to folders
- Moving and renaming between folders
- Copying and pasting
- Searching
- Access rights (read only)
- Sorting (date modified, name)
- Overall file system for organising (NTFS)
1.5.2 Utility software
Utility software helps maintain the system. It includes programs involving encryption software, defragmentation and data compression tools. Computers often come with these software built in (even part of the OS now) to keep the device running smoothly.
Encryption software
Encryption software is used to scramble the contents of files to everyone but authorised users who have the decryption/private key. It can encrypt individual files or even the entire disk! This is useful for government organisations or banks which have private and sensitive data stored. If someone steals a disk, what can they do with the data if they can’t read it?
Defragmentation software
If you know what defragging a hard disk is, then you can skip this.
If you don’t, read below:
Hard disk drives are separated into thousands of tracks, with thousands of segments in these tracks. When a file is written to a disk, it is written to the next available segment. Let’s say you’re downloading a 30GB game - and you pause it halfway through for an hour, and you download some music. Then, on the hard drive, you will have some of the game, then some music. Let’s say you finish the download. Then, there will be some game, some music, and the rest of the game. Oh, also, how about some programs were updating in the background and it didn’t say! Then, there will be loads of ‘fragmented’ parts of games, programs and music, all jumbled around near each other on the disk!
This is terrible for the computer’s performance, as the head has to go to loads of physically distanced parts of the disk to read and write to. Defragging moves the files from all these parts to one consecutive track, where possible. This will load your games up a load faster!
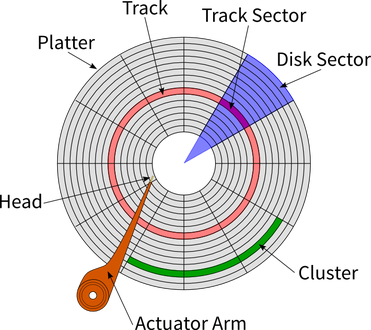
What a hard drive is actually made from. Remember there can be several platters on a large drive!
NOTE: Solid state drives’ speeds are not affected by fragmentation. Do NOT EVER try and defrag a SSD!
Compression software
Compression software reduces the size of a file on secondary storage to make it easier to send (as lower file size = lower packets needed) and allows more files to be stored (as lower file size = more free space). Note that most compression will need to be lossless, as you can’t just get rid of a bit of a program and hope it’ll work. Examples of compressed data are ZIP files.
Backup software
Now this isn’t in the specification, but I think it’s worth knowing about.
Backup software takes a copy of the files on a computer to either a high capacity secondary storage device (usually removable so a USB drive or big HDD) or uploaded to the cloud.
It can be a full backup or an incremental backup which takes place. A full backup is making a copy of every single file on a device, so will take a lot of time and storage space. Incremental backups only take a copy of new and modified files since the last backup, so they’re cheaper and faster. Usually admins will take one backup at the start then daily incremental backups.
Remember, it will take a long time to download from the cloud, so if there’s a question on this then remember that. Then again, cloud documents can be accessed from anywhere…
1.6 Impacts of digital technology
Advance information: The following will be directly assessed:
- Impacts of digital technology on wider society
- Legislation relevant to Computer Science
1.6.1 Ethical, legal, cultural and environmental impact
Here’s what the specification says on this subtopic:

Impacts of digital technology on wider society including:
- Ethical issues
- Legal issues
- Cultural issues
- Environmental issues
- Privacy issues
Ethical issues occur when a given decision, scenario or activity creates a conflict with a society’s moral principles.
A legal issue is something that happens that has legal implications and may need the help of a lawyer to sort out - a question or problem that is answered or resolved by the law.
Cultural issues are problems that occur when culture conflicts with systems, goals or other cultures. (e.g religion, ethnicity, generation)
Environmental issues are defined as harmful effects to Earth and its natural systems due to the actions of humans. (e.g pollution, animals dying, poisoning of environment, deforestation)
Privacy issues include companies using your personal data for their gain, e.g TikTok seeing what trends you’re into and giving you ads across other websites, which then track you and build up a profile of what you do online. To some people this would be creepy, especially as there’s no way to opt out
If in doubt, just say that’s what tiktok do because you’ll probably be right either way
Legislation relevant to Computer Science:
- The Data Protection Act 2018
- Controls how your personal information is used by companies, organisations or the Government.
- Computer Misuse Act 1990
- For securing computer material against unauthorised access or modification
- Copyright Designs and Patents Act 1988
- Gives the author or creator the right to copy, adapt, communicate, lend or sell copies of their work (can be sold or transferred)
- Software licences (i.e. open source and proprietary)
A software license agreement describes how the software should be used, and any restrictions it may have from the author, the provider and to end users.
Open source means providing access to the source code and the ability to change the software if you want. Groups of programmers often work together to provide support for users and develop the software further. These products are often tested by contributors in public. FREE TO USE, FOR ANYONE.
For example, BaguetteBot (Source Code + Invite Link) is free to use and inspect my code.
Proprietary means no access to the source code (already compiled), purchased commonly as ‘off-the-shelf’ for example games. Also known as closed-source. It remains the legal property of whoever made it. Source code is usually not released, and may require a license key to use it in return for money.
Developers of proprietary products are expected to create tutorials and support many operating systems themselves, especially if the product costs money.
In short, if you want to make money, use a proprietary license. If you want people to improve your code and find bugs, use an open source license. You will need to recommend a type of licence for a given scenario, including benefits and drawbacks.
Paper 2
IMPORTANT: THERE IS NO ADVANCE INFORMATION ON THIS PAPER. YOU NEED TO KNOW EVERYTHING.
2.1 Algorithms
2.1.1 Computational thinking

There are 3 words to describe ‘computational thinking’:
- Abstraction: filtering out and ignoring the parts of problems which are not needed to solve a problem. It is effectively a general overview of the program with specific details removed, for example the London Underground map.
- Decomposition: Breaking down a problem into smaller parts which are easier to understand. These smaller parts can be individually solved as they are easier to comprehend, for example creating an app would need graphics, audio, software used to create it, testers, user interface…
- Algorithmic thinking: thinking logically, just as a computer does. Usually works back from how an intended solution can be reached by working out the steps needed to get there.
Sometimes I might get annoyed if you don’t think algorithmically…
It is only when a problem is decomposed and abstracted, that creating of the algorithm can begin,
2.1.2 Designing algorithms
An algorithm is a step-by-step set of instructions used to solve a problem. Before designing an algorithm, it must be decomposed into its inputs, outputs and the order of instructions, as well as if any decisions need to be made.
Algorithms are made in three different ways: pseudocode, flowcharts and in Python (or another high-level language/OCR reference language).
You need to know how to create, interpret the results of, complete and refine algorithms in these languages. If you can’t code Python, please just get up replit or an IDE and start coding. You will find my examples at the bottom.
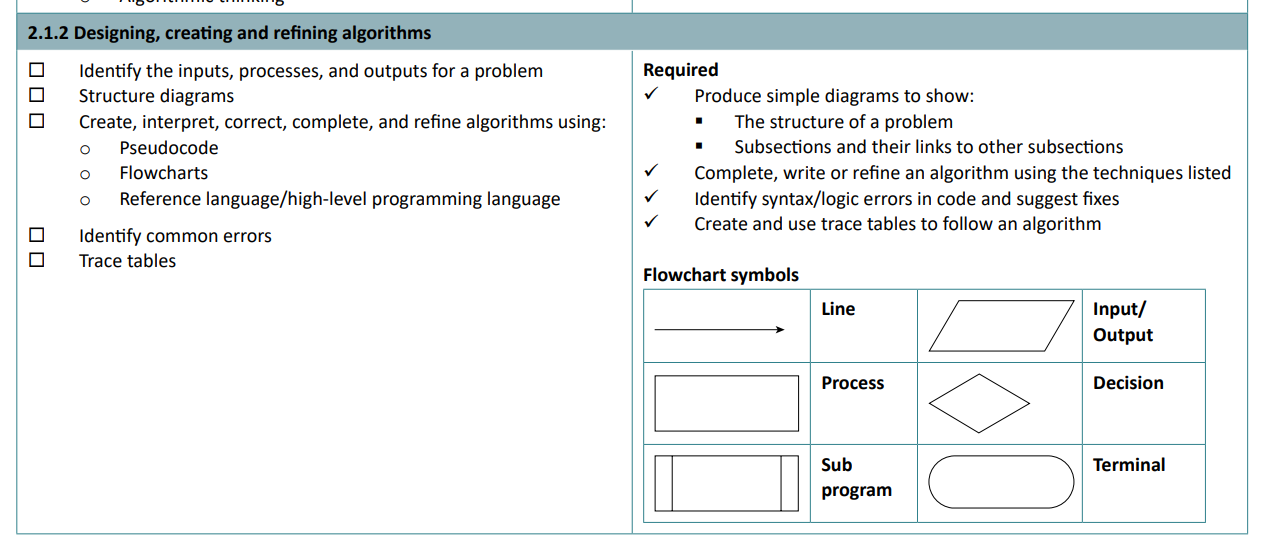
Flowchart symbols
- Lines represent the flow of the program.
- Parallelograms show inputs and outputs.
- A rectangle shows a process, for example
x = x + 10 - A diamond represents a decision, for example if
x > y. Then there would be 2 lines coming from this, one for yes and one for no. - A rectangle with curved sides represents a terminal, like the start or end of the program.
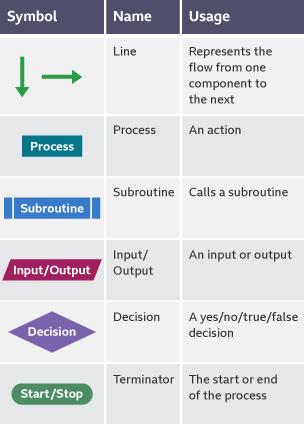
Make sure you know this. Credit BBC
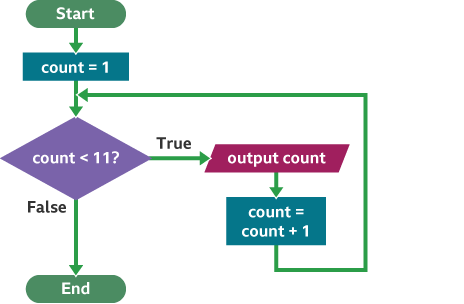
Example use. Credit BBC
Creating programs
Advantages of using flowcharts include the fact that it shows a step-by-step method of how to solve a program, which can be easily written. Disadvantages of flowcharts include that they may be time consuming to make and not easily drawn.
Advantages of using pseudocode (looks like real code but won’t run) include it acts as the foundations for transcribing it into an actual programming language like Python, and is easy to understand with an English-like syntax, like Python, making it easy for non-programmers as well, like Python. Errors in the design will not affect the program as it is obvious what the intended result is, and if there is an obvious error this can be easily changed.
Disadvantages include that it can be harder to see how a program flows with indentation, and is just more time consuming to make than a flowchart, so you might as well use Python for that.
Pseudocode example
while answer_inputted != 'valorant'
answer_inputted = input ("what is the worst game")
if answer_inputted == "valorant" then
print("correct! you got it right.")
else
print("wrong")
endif
endwhile
It’s easy to tell what this ‘code’ does.
- Line 1 says the loop will repeat
whiletheanswer_inputtedis not'valorant'. - Line 2 sets variable
answer_inputtedto the outcome of theinput - Line 3 checks
ifanswer_inputtedis'valorant' - Line 4
printsa response - Line 5 is
elseso this will be used when the previous statement is nottrue(if theanswer_inputtedis not ‘valorant’) - Line 6 will
printwrong - Line 7 will end the if statement after the if statement is triggered
- Line 8 will end this section of the code when the endif statement is triggered
Trace tables
A table used to show how values in variables change throughout instructions occurring.
In the columns goes the variable name. In the rows, the instruction number is written. Below the variable names, in the table, are the expected values of what each instruction does.
A logic error has occurred if the expected value on paper does not equal the received value when executed by the programrs
They enable a programmer to compare what the value of each variable should be against what a program actually produces. Where the two differ is the point in the program where a logic error has occurred.
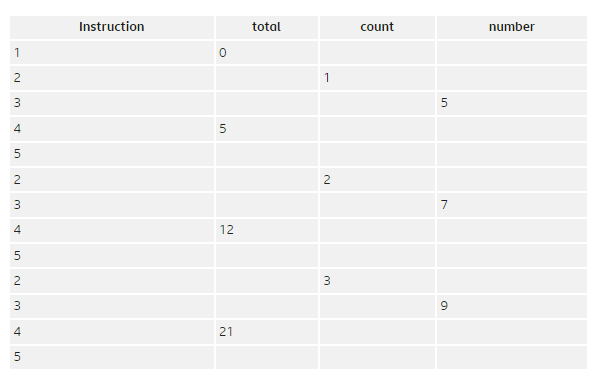
from bitesize
https://www.bbc.co.uk/bitesize/guides/z4cg4qt/revision/9
2.1.3 Searching and sorting algorithms

Linear search
The simplest method of searching through a dataset. It gets the length of a dataset, sets it counter to 0. It looks at the position of its counter and sees if it matches the search. If not, the counter is incremented by 1 and the process is repeated
Linear searches work on unordered lists. On ordered lists, they will take a long time if the value to search for is a large number.
Binary search
Binary search is used on a dataset of pre-ordered numbers. It works by:
- getting the midpoint in the list, getting the value, and if it is the target value the search ends.
- If not, it will compare the received value. If the value is less than the value to be found, it will disregard the lower half of the list, as it knows it cannot be lower than the midpoint value.
- The remaining part of the list is divided in half again, and the process repeated.
- When the value is found, the search has succeeded.
Note: rounding applies. If there are 7 items in the list, the midpoint would be 3.5. In this case the search would start from 4.
Binary searches are much more efficient than linear searches, especially on large datasets.
In an ordered list of every number from 0 to 100, a linear search would take 99 steps to find the value 99. A binary search would only require seven steps.
Bubble sort
- Starts at the beginning of the list, compare the value at position 1 to the next one up (at position 2).
- Swap the positions of these if the second is bigger than the first.
- Then, move both positions up one, to position 2 and 3.
- Swap if they are in the wrong order.
- Repeat until the end of the list.
- Start back from the beginning and repeat this until it is in order.
https://www.bbc.co.uk/bitesize/guides/zjdkw6f/revision/4
Merge sort
Very simplified version:
- Split the list in half repeatedly until all values are separate
- Compares two values next to each other and organise.
- Go to the next pair of values and repeat. If something is smaller than the existing smallest value, then place it there instead. (Same with biggest values)
- Repeat until all values are in order
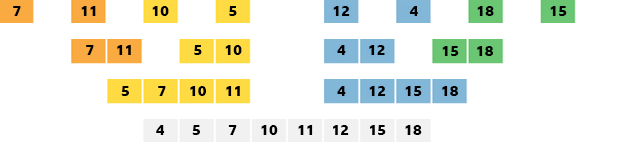)
bitesize version
Large data sets are better with merge sorts as they are more efficient.
https://www.bbc.co.uk/bitesize/guides/zjdkw6f/revision/5
Insertion sort
More efficient than bubble sort, but less complex and efficient than a merge sort
- Compare values of 1 and 2.
- If 1 is bigger than 2, then 2 is moved to the start.
- Compare the values of 2 and 3. Move 3 to the left until it cannot be moved any more as the number is smaller than it.
- Repeat for all values.
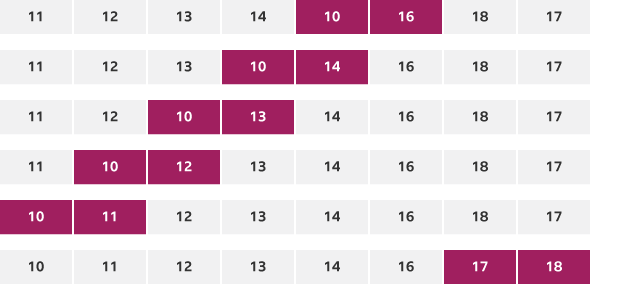
bitesize version
Insertion sorts work best when used with smaller data sets.
https://www.bbc.co.uk/bitesize/guides/zjdkw6f/revision/6
2.2 Programming fundamentals
2.2.1 Programming fundamentals

Basic programming definitions
- Variables: A value stored in memory that can change.
- Constants: A value stored in memory that cannot change once defined.
- Operators: Logic applied to numbers, e.g equal, subtract, less than.
- Inputs: data inputted to programs. In python,
x = input("enter string: ") - Outputs: data the program shows to users.
print("output") - Assignment: giving a value data. e.g x = 2. you are assigning the value
xthe data, which is2, an integer.
Sequence is the way in which the code is executed.
Selection is a part of the code that is ran, or if statements. When these statements are encountered, it ‘selects’ which part to run!
Iteration is a loop. There are count and condition controlled loops.
- Count controlled loops are controlled by a number. For example,
if x > 10:will run until the value ofxis greater than10. - Condition controlled loops are controlled by a specific value. This is most often
TrueorFalse; these will run until this value is changed. For example,if x == True:will run the code until the value ofxis no longer equal toTrue.
Operators
There are comparison and arithmetic operators. (They will give the boolean value of True if their criteria is met)
Comparison operators:
- ==
- Equal to. Used only to check if a value is something else. Do not get confused with a single equals which is used to specify a value.
- !=
- Not equal to. Only
Truewhen the value it is comparing against is NOT the first value.
- Not equal to. Only
- <
- Less than. Only
Truewhen the value in front of it is less than the value after it.if x < 3means if x is less than 3.
- Less than. Only
<=- Less than or equal to. Only
Truewhen the value in front of it is less OR equal to than the value after it.
- Less than or equal to. Only
>- Greater than. Only
Truewhen the value in front of it is more than the value after it.if x > 3means if x is greater than 3.
- Greater than. Only
>=- Greater than or equal to. Only
Truewhen the value in front of it is more OR equal to than the value after it.
- Greater than or equal to. Only
Arithmetic operators:
+- Addition. 9 + 10 = 21
-- Subtraction.
*- Multiplication
/- Division
MOD- Modulus. Gives the remainder. 20 mod 8 = 4. (16 remainder 4)
DIV- Quotient. Gives how many times the number can be fully divided. 20 div 8 = 2. (20 divided by 8 is 2 remainder 4.)
^- Exponentiation. To the power of. 2^8 = 256.
Boolean operators
- AND - only True when the two values are True.
- OR - only True if one or more values are True.
- NOT - everything that is not the value.
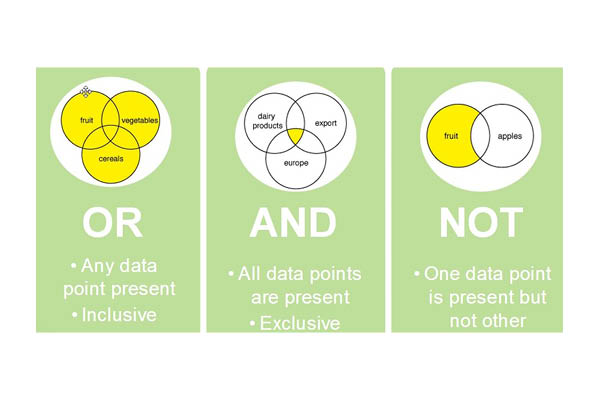
2.2.2 Data types

- Integer: Positive or negative whole numbers
- Real/float: Numbers with decimal places
- Boolean: True or False (1 or 0)
- Character: A single character
- String: Numbers and letters together.
Casting is a method used to convert between these data types. For example, if you want to compare a user’s input to a value, you must change it to an integer first. The way to do this is by using:
x = input("how much cake do you want from to 10? >>")
if int(x) > 5:
print("you really want cake lol")
You use int(x) to change x to an integer.
Or, str() for strings, or float() for floating point data.
You can turn the above into two lines by using this:
if int(input("how much cake do you want from to 10? >>")) >5:
print("you really want cake lol")
2.2.3 Additional programming techniques
THERE IS A LOT HERE I WILL BE QUICK
String manipulation
Not manipulating surds, or abusing strings, but just messing about with the sting.
The length of a string can be obtained by doing len(string), where string is a variable holding a string value.
You can also get the characters at a specific point in a string. If x = ‘Baguette’, then x[3] would be ‘u’. Remember 0 is your first value.
To get the characters from positions 0 and 3 (not included), the syntax is this: x[0:3] = would be ‘Bag’. This is known as ‘slicing’.
You can also manipulate the casing of everything in a string. If x = ‘Baguette’, then x = x.upper() would result in x being ‘BAGUETTE’. Likewise, x.lower()would be ‘baguette’.
Finally, concatenation is joining two strings together.
If one = "Baguette" and two = "Brigaders", then one + " " + two would print Baguette Brigaders.
If you feel comfortable with f-strings then you could get the same by using
print(f"{one.lower()} {two.upper()}")to output ‘baguette BRIGADERS’.
(2D) Arrays
Arrays (interchangeable with lists honestly) store lots of stuff and are denoted by their square brackets, like [4, 5, 3, 6, 9] or with strings as ["Yes", "No", "Baguettes", "Beans", "Haram"]. They can be accessed by the sting name and location in the list. If the above list with strings is called random_words, then to print the word ‘Baguettes’ I would call print(random_words[2]).
2D arrays take this principal and make it more complicated. Basically this means there is an array inside an array.
list_of_cars_and_prices = [["beans car", "bozo car", "fresh car"], [20, 30, 55]]
Notice how inside one list, there are actually 2 smaller lists? This is a 2D array. To get the value of ‘55’ from the second array, we do print(list_of_cars_and_prices[1][2]. This gets the third value from the second array, inside the list called ‘list_of_cars_and_prices’. This can be used to store values next to each other.
To change a value of an item in an array/list, do
list_name[index] = "thing_to_change_it_to"
Functions and procedures
A procedure performs a task, whereas a function produces information.
Parameters can be invoked into both functions and procedures. For example, beans(number_of_beans) will result in the function or procedure using the invoked value of number_of_beans to perform a calculation.
Functions return a value. You can assign a value to a variable, and set this value to the result of a function, like x = beans(), where beans is a defined function. It could return a number or string or any data type.
Programming languages have their own built-in functions and procedures. When you type
print("text"), you are actually passing in yourtextas a parameter used to display something on your screen! User-defined functions and procedures are the ones that the user creates.
File handling
writing:
file1 = open("file.txt")
x = file1.write("AMONG US FRENCH SUSSY BAGUETTES")
file1.close()
reading back:
file1 = open("file.txt")
x = file1.read()
file1.close()
print(x)
must always do file.close() to avoid corruption
Locals and globals
Global variables are accessed by every subroutine at all times. Present in memory during execution. Bad because if it gets maliciously changed than it could affect the entire code and every subroutine. Also memory hog if loads of variables are used at once - normal in big programs and games. Scope of these are the entire program.
Local variables are declared in one subroutine or function. The value of this is only held in memory whilst that part of the code is being executed. Therefore it’s more efficient. Scope of these are the sub-program of declaration.
Parameter passing - allows the values of local variables within the main program to be passed to sub-programs without the need to use global variables. The value of these variables (or a copy of the value of these variables) is passed as a parameter to and from sub-programs as necessary.
SQL
SQL is a programming language used for interrogating a database.
Data can be retrieved using the commands SELECT, FROM and WHERE
* stands for wildcard, which means all records.
from the ibaguette emails database:
SELECT * FROM "Users" WHERE "Email Address" LIKE "admin" OR "draggie"
would retrieve:
1 Draggie 306 Superuser [email protected]
6 Admin Beans Administrator [email protected]
7 Draggie1 306 [email protected]
ID User Surname Email Address
i’m tired please just click this until it might get updated.
Randoms
You must import randomat the start of the program for this to work.
random.randint(lower_bound, upper_bound) is used to generate a random number between bounds. Assign this to a variable and you have your randomly generated number.
2.3 Producing robust programs
3.1 Defensive design

A program must be able to handle all likely input values, not just the intended one. If valid data is inputted which might affect functionality, for example entering -10 to an age question, then this will produce logic errors. To accommodate this, there can be a range of things added to a program to ensure these do not occur.
- Anticipating misuse
- A way of making sure age is not negative could be by making the part of the code that verifies age a function, which will return the age once verified to be valid. For example, a while statement could be added with a condition controlled loop, which will only change conditions
if age > 10 AND age < 100. This is an example of input validation
- A way of making sure age is not negative could be by making the part of the code that verifies age a function, which will return the age once verified to be valid. For example, a while statement could be added with a condition controlled loop, which will only change conditions
- Authentication
- Usernames and passwords. This can be easily implemented by adding
password = input("enter password")and using double equals to check if it matches a previously defined variable, or even decrypted from an external file.
- Usernames and passwords. This can be easily implemented by adding
Code written must also be maintainable in the future. There are several ways of ensuring this.
- Subroutines. These are parts of the main program. If one part of the program needs to be changed, it can be in the subroutine which is called, so other parts of the code are not affected by changes. Also, it can reduce the amount of clutter in code as if something needs to happen multiple times, code can just link back to a pre-existing subroutine.
In BaguetteBot, whenever someone generates coins in the server, one subroutine takes care of this, instead of it being defined how to exactly add a coin whenever someone asks for their balance, joins voice chat, sends a message, etc. Type .coins to use it in Baguette Brigaders!
- Naming conventions. There is a set of rules you should follow when naming variables and subroutines. For example naming something
xdoesn’t really tell you what it does, whereasvalue_inputtedwill. (I’m very guilty of this!) - Indentation. Essential for legibility, indentation also defines if statements and more. It also makes it easier to read what parts of the program does, as indented levels show that everything on that indent is as a result of something previously.
- Commenting. Helps people read your code and helps you come back to work on it later. Denoted by either
#,"""or//, depending on the language. The first two are for Pythion.
2.3.2 Testing

Testing is used to make sure there is no bugs or unexpected events when the code is run. You don’t want to send your code to a client if it doesn’t work!
Logic errors result in the program still executing, but producing unexpected results.
Syntax errors are errors which break the grammatical rules of the programming language and stop it from being run/translated into machine code.
Il existe deux exemples de tests :
- Iterative testing. This is testing the code, or parts of it, during development to ensure there are no seriously buggy things happening as a result of a typo. It may be easier to identify the mistake if the code is run every few minutes, as the programmer will remember what they’ve changed.
- Final/terminal testing. This is testing which occurs at the end of production of some code, before sent to clients.
Normal test data is data which should be accepted by a program, without causing errors
Boundary test data as data of the correct type which is on the very edge of being valid. For example, in the statement if x > 10, the boundary would be 10.
Invalid test data is data of the correct data type which should be rejected by a computer system. This could be like if an age is -100 years old.
Erroneous test data as data of the incorrect data type which should be rejected by a computer system. This could be entering a name instead of an age.
You need to know how to identify suitable test data for a scenario, and how to create and complete a test plan. By putting in ‘erroneous’, ‘boundary’ and ‘valid’ during iterative testing and final testing, this will get you full marks.
2.4 Boolean logic
2.4.1 Boolean logic
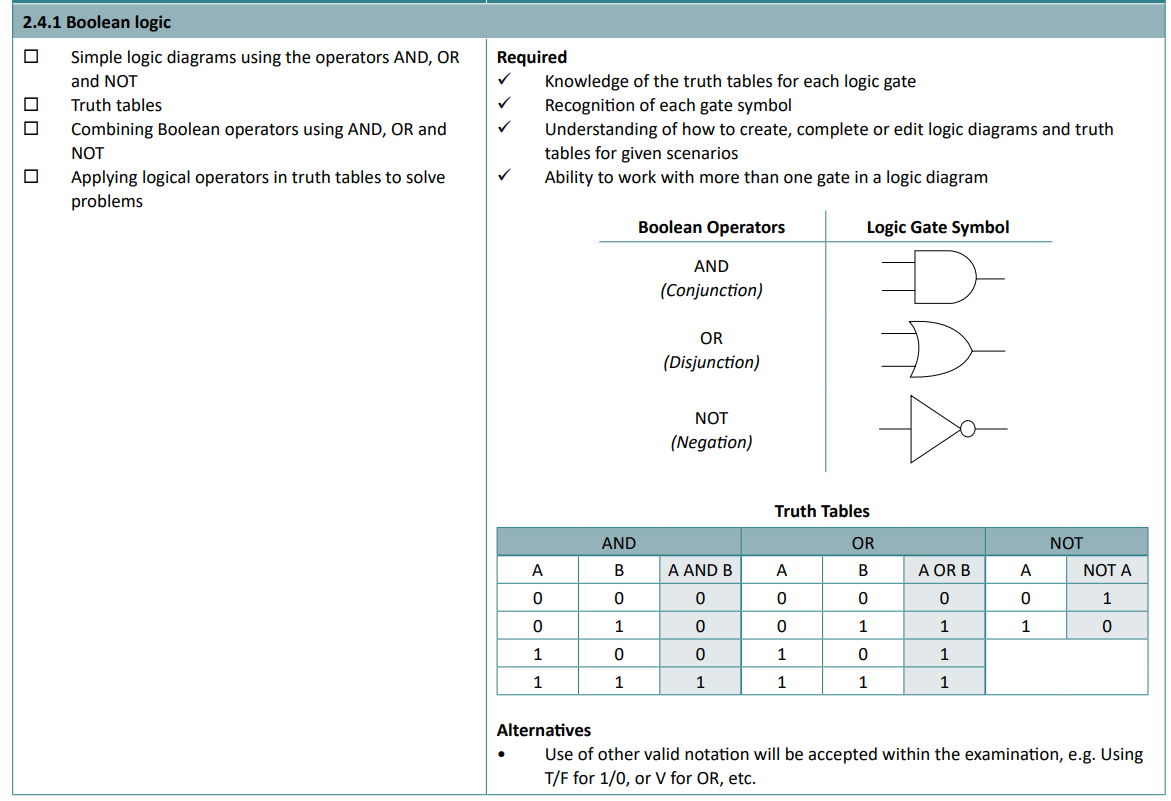
Ahhh… logic diagrams and truth tables. My worst enemy. There’s always a tricksy little 1 or 0 that I always put in the wrong place and there goes my full marks for the test. Grrrr!
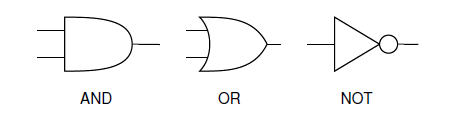
Your and or and not gates
You must be able to follow the lines in a truth table, and the interactions these have at these gates.
- An AND gate will only output 1 if both its inputs are 1 as well.
- An OR gate will only output 1 if one or more of its inputs are 1.
- A NOT gate will only output 1 if its input is 0. (Essentially reversing the input)
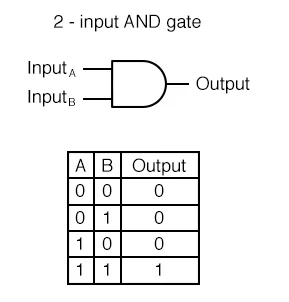
AND gate outputs
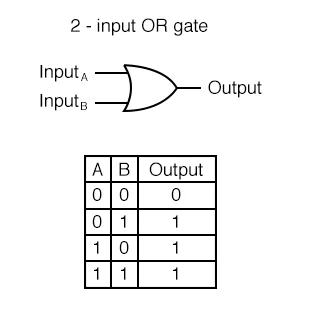
OR gate outputs
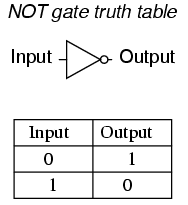
Deez NOTs
You don’t have to know this lol
2.5 Languages and IDEs
2.5.1 Languages

Lae français est aussi une langue mignonne mdr. attendre, je n’ai dit jamais ca, d’accord ? Merci. 👀
There are two categories of programming language: high and low level languages.
- High level languages are those which sensible people code in, like Python, JavaScript, HTML. They are easy to read and write, and some have a human like syntax. They do not depend on the physical architecture of the processors executing them. However, as they are machine independent, they must be translated in order to run.
- Low-level languages like assembly code and machine code. They must be changed depending on the make and model of the CPU. As they run ‘closer’ to the CPU itself, they often require less overhead on tasks, and machine code does not require translation as it is written purely in binary.
Assembly code, although is a low level language, not quite machine code. Machine code is what everything must be translated into in order to be executed.
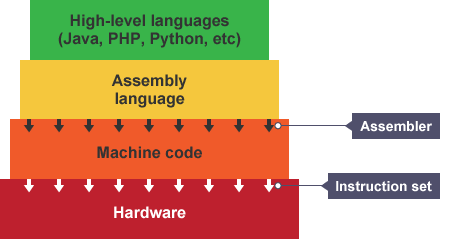
Stolen from here
A compiler parses the source code once, saving the results as a binary file, translating it. An interpreter reads the source code line by line and converts it to executable binary while executing.
Compiled code runs faster, as they have already been translated. If the code has no logic or syntax errors, and does not need to be debugged, compiled code is always better. It optimises code as well, allowing it to take up less memory. For example, comments are removed when generating compiled code. However, compiled code may also only on the hardware and OS it is targeted to. You can’t run an EXE file on your phone without an IDE.
Interpreted code is slower, as the CPU must wait for every line to be translated, but has the potential to run on multiple kinds of hardware, running different operating systems. It simply executes code, without saving a machine code version. They require less memory also as they do not translate the entire file.
Interpreters can be built with a REPL, or a Read Execute Print Loop. Hence the name repl.it.
2.5.2 The IDE

The IDE (integrated development environment) has a wide range of tools to help programmers develop programs. These include:
- Editors. Code can be edited.
- Error diagnostics. Tracebacks can show what caused exactly what to fail at the exact line.
- Run-time environment. This allows a program to run on a computer even if it was not designed to. This allows the programmer to just use their known high-level language, and the RTE will do the rest.
- Translators. They translate code to be executed hehehehaw.
You can also write about:
- Breakpoints - code can be stopped at a specific line and variables can be checked for logic errors
- Auto correct and indent
- Auto suggestion - can sometimes fix a problem automatically
- Syntax highlighting - similar declarations can be coloured to see them better. For example, all variables could be yellow while classes are blue.
- Linting - the IDE can analyse the code you’re writing as you’re writing it for errors. For example, it may recognise that you used a double equals instead of a singular equals for setting the value of a variable.
That’s it! Go get a grade 9! Of course you need to do some of your own programming, so a few examples are below for you to have a go at.
Programming examples.
Level: Easy
- Randomly generate a number and have the user guess it. If the user makes an incorrect guess, then say how far out the user is. The maximum amount it can be is the user’s input. Maximum 20 lines.
My example. Download Python / txt
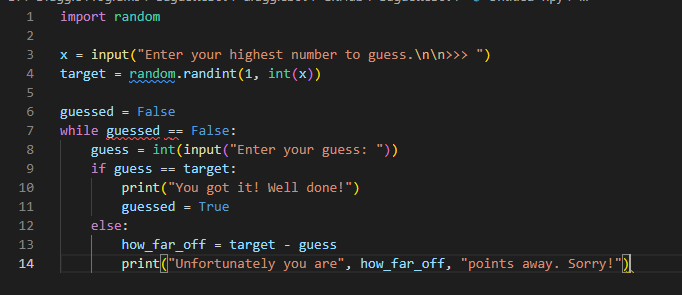{kind=link}
Level: Warm
- Write a program using functions and subroutines that checks an inputted age, through a menu. The function which checks the age must have a condition controlled
whileloop and the age must be between 10 and 100 years old. When done, return to the original function and print the age in a piece of text. Maximum 25 lines.
My example. Download Python / txt
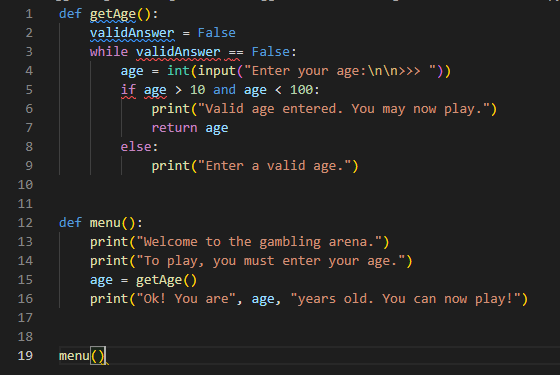{kind=link}
Level: Spicy
- Create a list of cars, each with a cost. The user can buy a certain amount of cars, with 100 coins. The user cannot buy the same car twice. Display these cars at the end when the user has no money left. Use a singular 2d list to store the available cars, the costs and owned cars. Maximum 20 lines.
My example. I used f-strings and more to make it look more complicated. Download Python / txt
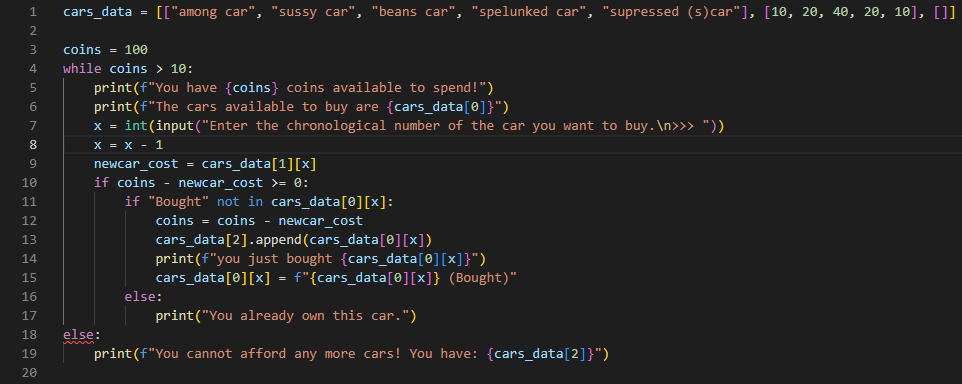{kind=link}
my IQ has increased
ReplyDelete