< Back to A level Cheat Sheets
A Level OCR H446 Computer Science
Welcome to the A Level OCR Computer Science H446 Cheat Sheet, with everything covered in detail in the specification.
This Cheat Sheet is in development. Unfinished sections are marked with [tbd] and there may be general issues and typos. ⚠
Last general update: 16/12/2023 19:42.
Last content addition: 04/12/2023 20:57
✅ Note: This file is synced with this repository. You’ll always be on the latest version.
Use a PC/device with a large screen to see the Table of Contents on the left-hand side to quickly navigate through this document.
Discuss with other friendly students, developers, educators and professionals in the Baguette Brigaders Discord server! You can also receive notifications when there are new Cheat Sheets, Summary Sheets (new!) or other revision material is made public there!

As always, enjoy this amazing high-effort and high-skill art by me.
Paper 1
[tbd] Unit 1 - The characteristics of contemporary processors, input, output and storage devices
Components of a computer and their uses
Surprisingly, a computer has a lot of things in it to make it work! These things are often very small but very fast.
1.1.1 Structure and function of the processor
The CPU (Central Processing Unit) has many different components within it, each having their own specific function and role. Its purpose is to process data, which can be searching, sorting, calculating, communicating between input/output devices, temporarily storing results of calculations, etc.
Buses
There are three types of bus, which all do different things and have different directions
Buses themselves are physical, parallel wires, typically visible on a motherboard, that connect two or multiple components together. These wires, or lines, are typically arranged in multiples of 2 with eight or more, such as 8 16, 32 or 64 individual lines. A bus is the entire collection of these parallel wires going from one component to another. [1]
The CPU is connected to RAM by three separate buses, the address bus, data bus and control bus. These are collectively known as the system bus. As each bus is shared, only one device can transmit along a bus at any given time.

Motherboard bus lines
Control bus
The control bus exists to distinctly transmit command and control, timing and status information between components of a system. It is bidirectional, as signals need to be transmitted in both directions.
WIthin the control bus, there are control lines. These are needed to ensure there is no conflict between different system components using the data and address buses. These control lines include:
- Memory Read (RD): Data from the addressed memory location should be added on the data bus.
- Memory Write (WR): Data in the data bus should be written to the addressed location in memory.
- Bus Request (BR): A device is requesting use of the data bus.
- Bus Grant (BG): The CPU has granted access to the data bus.
- Transfer ACK (ACK): The data has been read (acknowledged) by the device
- Interrupt request (IRQ): A device (with lower priority) is requesting to access the CPU.
- Clock: Signals used to synchronise operations between the CPU and other components. A clock signal keeps the flow of data synchronised.
- Reset: The CPU will reboot if active.
Word length/size
Memory is divided into equal units which are called words, typically multiples of 8, such as 64 bits. Each word has a separate memory address.
Data bus
The data bus transfers data and instructions between components and is bidirectional. With an increased data bus width, more data can be transferred between components simultaneously or in one single operation.
A system with a 32-bit data bus can transfer 32 bits of data at the same time, or 4 bytes. If 8 bytes of data needs to be fetched from memory, this will take 2 different operations to fetch the data, resulting in increased delays.
For this reason, most systems have a data bus width that is equal to the word length of the CPU.
Address bus
The address bus width determines the maximum possible amount of memory addresses or locations that the system can adderss.
A system with a 32-bit address bus can address 2^32 (4,294,967,296) memory locations. If each memory location (word) holds one byte, the addressable memory space is 4 GiB.
How these buses link to assembly language programs?
Control Unit
The control unit (CU) within the CPU is responsible for controlling all operations that occur within the CPU in other subunits and registers of the processor such as the ALU (Arithmetic Logic Unit), and how this data is exchanged to other registers or moved around the system. These operations are dictated typically by the speed of the clock signal (in Hz).
The CU also regulates and controls the data sequence between the processor and other hardware devices such as system memory through the control bus, and can generate and interpret received control signals from these received instructions after having decoded it (using the opcode and operand) into a sequence to determine the instruction needed to be carried out.
This could be, as an example, fetching the address and data requested from RAM, determine that an arithmetic calculation needs to occur, and storing the resulting data back in RAM, or in other registers.
The Control Unit is the component of the processor which directs the operations of the CPU.
The ALU
The Arithmetic Logic Unit performs arithmetic operations on data. It consists of two parts - the arithmetic unit - this can include addition, subtraction, multiplication and division. It can also compare arithmetic values and return a binary value if, for example, A is greater than B.
The second part is the logic unit which includes logical bitwise AND, OR, NOT and XOR operations. Finally, it may also perform shift operations (binary shift) within a register, moving bits left or right.
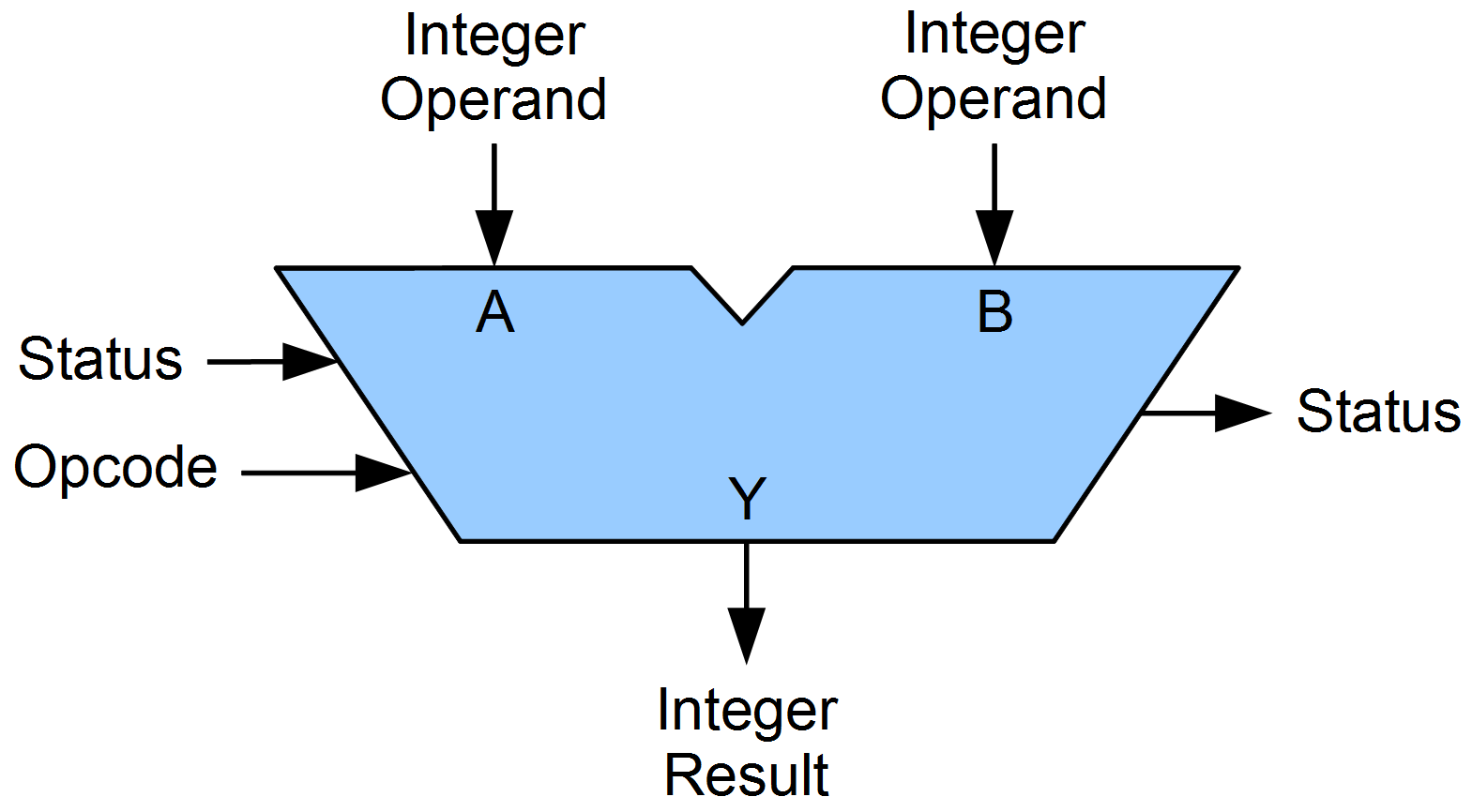
Credit: Lambtron/Wikipedia. License
{kind=link}
The ALU can compute integers of the same width as the data bus connecting to it - a 8 bit data bus can only provide the ALU with 8 bit integers. Multiple steps would need to be carried out in order to process larger integers, reducing efficiency of the processor.
Modern CPUs may also contain a FPU, or ‘floating point unit’, to handle floating point numbers more efficiently.
Program Counter (PC)
Holds the memory address of the next instruction to be fetched, decoded and executed by the processor.
Accumulator
Stores the ‘intermediate’ results of the data being processed at the current moment in the FDE cycle.
The final results get stored in another register such as the Arithmetic Logic Unit, or get moved to main memory.
Memory Address Register
Holds the address of the current memory location that is to be read or written
Memory Data Register
Stores the intermediate data that is to be written to, or read from, the current address in memory.
Current Instruction Register
Stores the current instruction being executed, with both the opcode (what instruction is to be executed by the CPU) and operand (the memory location of, or the actual data itself, used to execute that instruction)
The FDE cycle and its impacts on these registers
Factors affecting CPU performance
There are a number of factors used by CPU manufacturers in order to make processors faster.
Clock Speed
The FDE cycle is controlled by the system clock’s pulses. As a result, the faster this clock is, the faster a processor will be able to fetch, decode and execute instructions.
In modern systems, actions are executed on the rising edge of the system clock. These actions some time to complete (number of cycles).
https://opensource.org/license/bsd-2-clause/
The clock width is the length of one pulse - the shortest time possible between the rising and falling edges. The clock period is the length between two rising or two falling edges.
The clock speed typically changes dynamically in modern systems to balance power and performance, with some energy efficient machines lowering their clock speeds to, for example, 1.1GHZ, during times of system idling, and may then increase (“boost”) higher to 4.2GHz when launching a game is executed by the user.
The user can increase the clock speed of a CPU. This is known as overclocking. With a faster clock speeed, data can be fetched, decoded and executed more quickly leading to improved system performance. However, heat generated by the CPU will increase proportionally with clock speed, so this is only viable for systems with better heat dissipation.
The Core i9-13900K chip currently holds the record for fastest clock speed, reaching 9GHz. This dethroned the previous record set by an AMD chip in 2012, at 8.79GHz.
This was only managed under specialist, liquid nitrogen cooling conditions for a few seconds.
Core Count
A CPU core contains its own control unit, ALU and registers, allowing it to fetch, decode and execute its own instructions from memory and link to other processors on the physical CPU chip.
For systems and software designed for multi-core systems, this enables parallel processing. The same program can have two separate instructions being processed concurrently. This also facilitates multitasking, with each core being to process different programs’ instructions at the same time.
This is not always the case, with some programs being unoptimised for this, or require synchronous processing, when they require the result of one calculation before another, so cannot be worked on at the same time.
Cache
Cache memory is small amounts of fast memory that stores frequently accessed data and instructions to improve CPU performance. It is typically on the CPU chip. When data or an instruction is fetched from system memory, it is copied into cache in case it is needed by a register immediately. This has a reduced latency compared to fetching from memory as it does not need to travel through the data bus.
The CPU in reality checks for the data in the (L1) cache first and uses this before checking RAM - if it exists, it’s a cache hit as opposed to a cache miss.
Cache memory operates in a hierarchy of levels, with L1 cache being the fastest and closest to the CPU registers, but very small, often only 64KiB in size due to its expensive price.
L1 cache is also split into instruction and data caches, (L1i/L1d) so that both data and instructions can be fetched simultaneously. This is an example of Harvard architecture.
Due to this storage limitation, the least recently used data or instructions after several FDE cycles are relegated the higher-level L2 or L3 caches or copied back into main memory to prioritise newer, more important instructions.
L3 cache is much larger, perhaps up to 96MiB, but the tradeoff is slower access speeds.
CPU registers themselves could be considered as ‘L0’ cache - this is more of an analogy than fact, but registers are still much faster than even L1 cache.
Pipelining
Pipelining is a technique used by most modern processors so increase the overall performance of the processor.
This can be facilitated through overlapping stages in the FDE cycle. Without pipelining, all instructions are executed sequentially - the ALU remains idle when an instruction is being fetched. With pipelining implemented, different jobs are assigned to different stages in the FDE sycle simultaneously.
The next instruction(s) to be fetched can be fetched at the same time as the ALU is performing an operation on the current instruction, and stored in a buffer ready for execution, allowing for concurrent processing and improved throughput and efficiency through lower idle time.
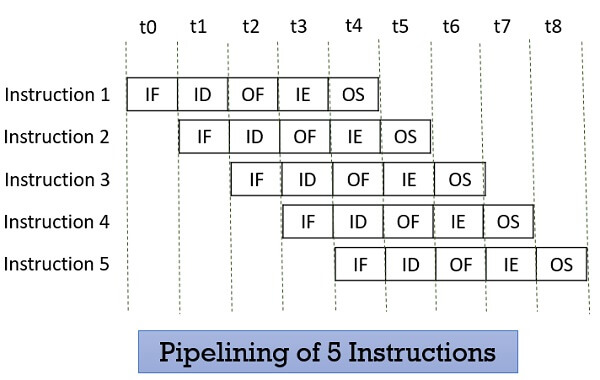
A more detailed diagram of how instructions can be pipelined. These stages are Instruction Fetch, Instruction Decode, Operand Fetch, Instruction Execution, and Operand Store, but you don’t need to know them. In a non-pipelined system, Instruction 2 would be fetched at point t5 and take until t9 to complete. Source
Contemporary Processor Architectures
There are two main architectures used in modern day computer systems.
von Neumann architecture
von Neumannn architecture is used in the majority of computer systems today. Program instructions and data are stored together in system memory, both using the same data bus to connect to the CPU.
This employs the stored program concept - where a program must be loaded into memory to be executed, its instructions are fetched, decoded and executed sequentially, and can only be changed by a jump/branch instruction.
Benefits of von Neumann architecture include that it is cheaper, and makes more efficient of use of available RAM. This is because if the data store were to become full in Harvard architecture, the data store could not store this. These memory addresses are in von Neumann architecture are unified.
Harvard architecture
Harvard architecture is mostly used in specialist and some embedded systems. A program’s data and instructions are stored separately in memory with a separate data bus connecting it to memory.
Digital Signal Processors make use of this by having multple data buses running in parallel for reading and writing signals whilst only one instruction bus
This could result in speed and efficiency improvements as the program and data instructions are no longer ‘competing’ for the same data bus.
Modern systems include aspects of both von Neumann and Harvard architecture, for example main memory is accessed through von Neumann architecture, but in order to take advantage of speed optimisations available, Harvard architecture is used by the CPU in its cache memory - hence why it has a distinct data and instruction cache.
1.1.2 Types of processor
CISC CPUs
Complex Instruction Set Computer.
This architecture revolves around having a large instruction set which is used to complete tasks in as few lines of assembly language as possible, such as combining the LDA and STA instruction with the calculation instruction such as ADD or SUB.
For example:
MULT A, B
would:
- Fetch data at memory address A and load to accumulator
- Load data in accumulator into ALU
- Fetch data at memory address B and load to accumulator
- Load data at accumulator into ALU
- ALU compute result of multiplication
- Move data from the ALU into memory address A
RISC CPUs
Reduced Instruction Set Computer.
This architecture has a smaller instruction set of simpler instructions. The key is that each instruction requires one clock cycle to complete.
Comparable to the above CISC instruction set, it may be written as:
- LDA R1, A (Loads register (R1) with data at memory location A)
- LDA R2, B (Loads register (R2) with data at memory location B)
- MULT R1, R2 (Multiples value in register R1 by value in register R2, outputting to register R1)
- STA R1, A (Copies contents in R1 to memory address A)
Comparison:
| CISC | RISC |
|---|---|
| Faster to create program code | Hardware is simpler to build, with fewer, more complex needed for instructions |
| The compiler has fewer amount of tasks to complete to translate a high-level language into machine code | Pipelining is easier as each instruction takes a known amount of time, being one clock pulse |
| Reduced RAM usage to store instructions due to smaller code size | RAM is cheap, so this is not a real concern, and program data will likely use more RAM than instructions |
| Hardware-based optimisation allows more complex instructions to be executed | Relies on optimised software techniques such as compiler optimisations to improve performance |
| Greater backward compatibility with older software and old applications which may be needed by datacentres | Easier to migrate to newer architectures as less instructions need to be rewritten |
GPUs
GPUs are co-processors. This means that they provide the CPU with the ability to offload computationally intensive tasks and accelerate certain types of calculations.
They can handle large amounts of visual data at once as they have thousands of small cores for this processing in parallel, making them much more efficient than the CPU for a minority of tasks.
They were originally designed to render images and graphics. Because they are designed to perform one instruction on many pieces of data in parallel, rather than various instructions on different data like in a CPU, they can be used to perform a variety of other jobs, such as machine learning, cryptocurrency mining, and modelling (e.g weather forecasting).
Multi-core and parallel systems
1.1.3 Input, output and storage
Virtual storage
[tbd] 1.2 Software and software development
1.2.1 Systems Software
Operating Systems
Operating systems are needed by all computers to manage communication with hardware.
The user can interact with application software which interacts with the operating system (or interacts with the operating system directly) which then interacts with and manages hardware through drivers.
When a system starts, the bootloader in ROM loads the operating system into RAM.
The OS provides various functions such as a user interface, memory management, interrupts and interrupt handling, scheduling and device driver management.
The Operating System hides the complexity of the hardware by providing a user interfact to the user. This can be through GUIs (graphical user interfaces) such as Windows, or through CLIs such as the Command Prompt or the Linux shell.
Memory management
Paging
Paging is a technique which does not require the allocation of physical memory in a contiguous manner (i.e. all next to each other, like when writing data to a hard disk). Available memory is divided into equal-sized chunks or pages (typically 4, 8 or 16 KB), which can be swapped from primary to secondary storage if needed.
If Program A requires 2 pages of RAM, it gets loaded into the first 2 memory addresses which correspond to these pages. Program B requires 3 pages, which get allocated after program A. Next, Program A terminates and Program C starts, requiring 4 pages. This program will be allocated non-contiguous pages, with 2 pages being before Process B, and 2 pages allocated after Process B.
This will be managed by the OS and a page table will be used to match each program’s virtual memory addresses to the corresponding physical memory addresses.
Virtual memory addresses are an example of abstraction by allocating each program with a virtual memory space, which the maps to physical memory. This allows for the operating system to enforce memory security and integrity, as well as allowing for virtual memory.
Developers can develop software without needing to worry about the specific memory layout for each system the program will run on.

An example of memory integrity enforcement on Windows 10 and 11.
Segmentation
Segmentation is the division of memory into segments which are typically of different lengths that correspond to a particular part of a program, such as a function or subroutine. Larger functions may occupy larger segments, while a print statement may only need a small segment of memory.
Both segmentation and paging is handled by the operating system.
Virtual memory
Virtual memory is a technique used by most operating systems to use a portion of secondary storage like a HDD or SSD as memory.
When a program requests access to a page in memory that is not actually in RAM, a page fault or hard fault is raised, requesting the operating system to swap the page from virtual memory back into RAM to be executed by the CPU.
However, this can cause two disadvantages. The main disadvantage of this is disk thrashing - when there is so much extra disk activity from swapping pages in and out of virtual memory that it slows down the performance of a computer. This is especially so on hard disk drives which have to actuate and seek to a specific location on the disk platter, increasing response times for programs.
Some areas of memory cannot be swapped in to and out of virtual memory, such as the operating system itself, which is in the “nonpaged” area. If a page fault occurs when the OS tries to retrieve data from this non-paged area, the system may crash.
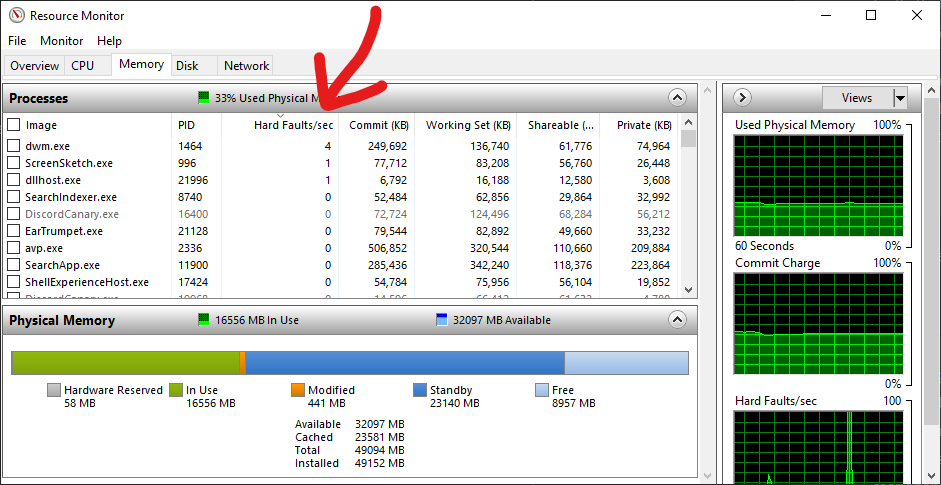
You can see how many hard page faults each program is having in Resource Monitor on Windows. As I have 48GB of RAM, my page file is only 1GB and I have little page faults. On other machines this may be much higher.
Programs can also share memory for similar tasks - for example a single developer may have multiple programs which have the same function in them. The operating system can handle this by giving both programs separate logical/virtual memory, but as only one instance of it in memory is required, this could be mapped to the same physical memory address, reducing memory consumption, allowing for more processes to use it.
Interrupts and the Stack
The CPU needs to be interrupted when necessary, preventing issues such as program corruption after an error, or system instability. Interrupts can be sent to the CPU by software, hardware devices, drivers, or its own internal clock.
Software can create an interrupt to request information from the OS (like an API call) and hardware can trigger interrupts when an I/O device has finished a transfer, a printer runs out of paper, or there is a power failure.
An interrupt is a signal generated by software or hardware to temporarily suspend the current execution of a program to handle a specific event or condition.
After every clock cycle, the CPU checks if there are any interrupts that require processing. If so, it uses an interrupt service routine to handle the interrupt. The CPU will typically push all current contents of its registers onto the system stack. When processing has finished, the values can be popped (as a LIFO data structure) from this stack and reloaded into the CPU. If there is not an interrupt at a higher level than the one originally being executed, the CPU then continues with the FDE cycle.
Scheduling
With multiple applications running concurrently, the OS needs to allocate processor time to each process or job, as one CPU can only process instructions and data for one application at a time. This is done through the scheduler. Its job is to ensure that CPU time is used as efficiently as possible to provide an acceptable response time to all users and programs, maximise the time that the processsor and its resources are being used and to ensure fairness on a multi-user system.
There are many scheduling algorithms which all have different uses and functions.
The scheduler has another component, the dispatcher, which is responsible for executing (or ‘dispatching’ the scheduled tasks by assigning them to available resources (i.e. the CPU cycles)
Processor starvation is when a process is unable to receive the necessary amount of CPU time to execute and complete its tasks.
First come first served
Jobs are processed in the same order as which they entered the queue.
| Advantages | Disadvantages |
|---|---|
| Easy to implement and test | Doesn’t prioritise more urgent jobs |
| No job starvation and fair for all running jobs | Doesn’t have priority levels |
| Suitable for batch processing systems | Can result in poorer system throughput overall |
| Can create a backlog if the initial prioritisation of jobs is long-running ones |
Round robin
Jobs are given a limited amount of processor time (a time slice or quantum) by the dispatcher to execute and complete. If the task fails to complete, the dispatcher moves to the nect job in the queue and allocates the CPU for this job.
| Advantages | Disadvantages |
|---|---|
| Guarantees a good response time for each job | Doesn’t prioritise more urgent jobs or priority levels |
| All jobs will adventually be processed | Longer tasks will be disproportionately longer due to inefficient splitting |
Note: in some implementations of RR, a job with a higher priority may be given multiple consecutive time slices or quanta. The best of both worlds!
Shortest remaining time
Jobs with the lowest estimated job time are prioritised. This can reduce the number of pending jobs that would otherwise be queued to execute after a big job. However it is difficult to predict which job will take the longest, especially in real-time operating systems or systems without any regular exection.
| Advantages | Disadvantages |
|---|---|
| Prioritises small jobs, for example background processes in batch systems | Difficult to predict which jobs will take CPU time - requiring a more advanced prioritisation algorithm |
| Reduces the number of pending jobs queued after a big job has completed | May lead to process starvation if there are lots of small tasks being added continuously |
| Increases throughput | More critical jobs may be delayed due to constant small job prioritisations |
Shortest job first
Similar to shortest remaining time. It still requires the processor to calculate how long each job will take and order the queue accordingly, but can also result in similar downsides.
| Advantages | Disadvantages |
|---|---|
| Waiting time is reduced in batch systems with small and predictable jobs | Longer response times for longer jobs |
| Increases throughput | Can lead to process starvation if small tasks are continuously added |
| Requires accurate timing estimation which may be complex |
Multi-level feedback queues
MLFQ scheduling is a feedback algorithm, which intelligently adjusts prioritisation of jobs over time based on behaviour. The knowledge that I/O devices and jobs that rely on these take longer to complete compared to a CPU cycle can result in these being prioritised over calculations, reducing bottlenecks.
While one job is transferring data onto a USB stick or printing, another job can be mining bitcoins which requires CPU[3] calculations.
| Advantages | Disadvantages |
|---|---|
| Reduces chance of bottlenecks and thereby prioritises jobs more efficiently | Difficult to implement |
| Processor use is maximised | More CPU resources may be allocated to insert the job into the queue rather than actually executing it for small jobs (overhead) |
| Combines multiple queues and can move jobs between them depending on their processor time | May result in process starvation for low-priority jobs if higher-priority jobs are constantly added |
| Allows for dynamic adjustment of different job priorities based on their historic behaviour, improving overall efficiency | Requires careful fine-tuning of its parameters to be fully effective |
| Over time, this may increase the overall system throughput on the majority of systems the most | Not suitable for all systems like embedded or realtime systems due to its dynamic nature and overheads |
The multi-level feedback queue algorithm is used in the majority of devices, including Windows 10 and 11. The “scheduler” has been a key talking point from Microsoft regarding benefits of Windows 11.
Types of Operating System
Distributed operating systems
The load of the OS is spread out over multiple physical systems or servers, sharing memory, resources and tasks. A job may be split into multiple tasks and each is run on different hardware devices.
Multitasking system
Most operating systems now allow you to run multiple programs at once, such as programming whilst talking to friends in a voice chat, listening to music, and having Stack Overflow up at the same time, whilst many of the core utility and OS programs are in the background.
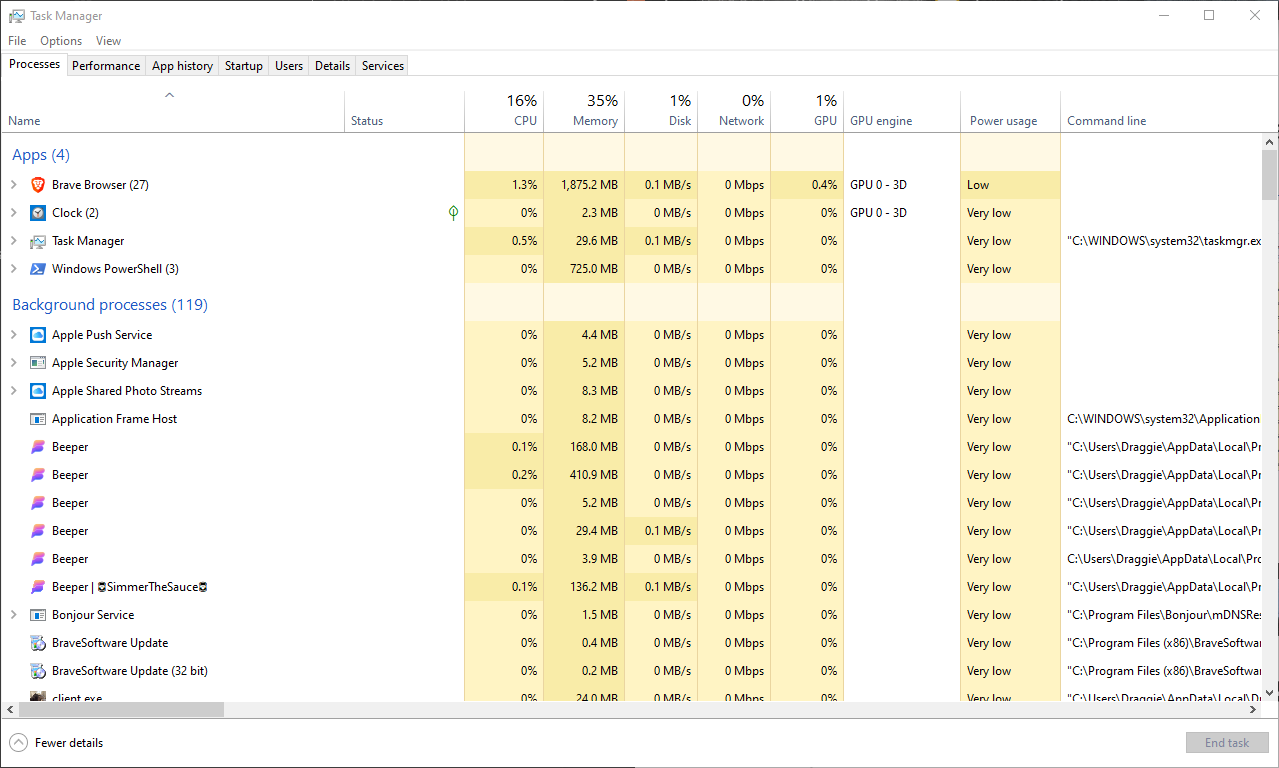
Here you can see the current applications I have open as well as background processes
Multi-user system
A single mainframe or supercomputer may connect to hndreds of terminals, all with different users on, and are allocated a time slice of the mainframe’s CPU according to a scheduling algorithm, typically Round Robin or MLFQs.
Realtime OS
Some safety-critical operating systems must operate in realtime and be able to respond to inputs and sensors as fast as posssible, and compute the results of multiple input devices concurrently. The OS must also have hardware (and even software) redundancy so critical components like the CPU may have duplicates or multiple ‘backups’ in place so that of one fails, another is automatically switched to
The BIOS
Stands for Basic Input Output System. It is stored in (EP)ROM and immediately initialises and tests hardware, then loads the operating system from a secondary storage device into main memory.
Device Drivers
A driver is a program that provides an interface to a particular hardware device, managed by the OS. This allows the OS to interact with a device and read its data without knowing the specifics of the low-level hardware being used. This driver may be downloaded from the Internet, or the OS may have a library of existing drivers when distributed, and when a new device such as a printer connects, it may check for an update automatically.
Virtual machine
A virtual machine is any instance when software is used to emulate another machine, such as running another OS inside another (e.g. Linux in Windows), emulating different hardware.
This may also include intermediate code, such as the Java virtual machine. This executes Java bytecode, which is machine independent, and converts it into machine code, which is dependent.
1.2.2 Applications Generation
Software can be split up and grouped into different categories.
Systems Software
Needed by the system to control hardware and run applications.
This may include:
- The OS - for resource management, a UI, processor scheduling and interrupt handling
Utility software
For the optimisation of the performance of the computer and performing useful tasks, sometimes in the background.
- Disk defragmenter for Hard Disk Drive optimises where blocks of data are stored on the platter, by moving it from physically fragmented locations across the platter, to one sector or track sequentially to improve seek and access times
- Automatic backup for files, especially important for businesses. They can allow users to specify where the backup should be, what should be backed up, how the backup should run (compression, incremental backup, mirror), when the backup should run (on a schedule, at specific times of day)
- Auto updating - checks servers on a scheduled cadence for new updates to software installed. This might be to add new software features, for antiviruses to update their definitions, or for the OS to patch vulnerabilities
- Antivirus - scans secondary and even primary storage for known virus definitions (requires regular updates), or use heuristic analysis to detect suspicious behaviour. They can run on a schedule, when files are read or modified, or when installed.
- Compression software can reduce file size for transfer or to save on disk space.
Applications software
General-purpose, special purpose or custom written (bespoke) software.
Ready made software is known as off the shelf software, and may include general-purpose software such as word processors or a graphics editing package. They are less expensive or free, well documented and tested.
Special-purpose software typically performs a single task or set of tasks. This may also be off the shelf for things like browsers, or be more ‘niche’ such as electronic exam marking applicaions or fingerprint scanning systems, or DBMS.
A bespoke software package may be bought by organisations for their specific needs like an inventory management system for a retailer. They are much more expensive and as they are tested less, could contain errors which are not known about initially.
Open source vs proprietary
Open source software has no charge for the license, and anyone can access its source code on sites such as GitHub. Depending on the license, developers may be able to modify and sell the software providing that the new software is also open source.
Freeware is free to use, but the source code is not available and have restrictions on use, e.g. businesses must pay for use but individuals don’t.
Closed source software or proprietary software does not allow access to the source code. There may be a limit on how many users are allowed to use it per copy of the software sold, according to its license, or be only allowed to be used on one specific site or company. Users must pay the person or company who wrote the software, and therefore own the copyright for it, to use it.
1.2.3 Software Development
Assemblers
Assemblers translate assembly code instructions into machine/object code. Each assembly instruction is 1:1 equivalent to one machine code instruction, which is dependent on the instruction set and the underlying type of processor and its architecture (hardware specific). Basic lexical analysis such as comment removal occurs here too.
Compilers
Similarly to assemblers, compilers translate the source code into machine code. After various analyses take place on this source code (see below) compilers produce object code, which is machine dependent. This code can then be run without having to be compiled again. EXE files are an example of compiled code.
Interpreters
Interpreters are more designed for development, with it going through source code line-by-line, and only translating it into machine code if there are no syntax erros. This compares to compilers, which will translate the entire source code before it is executed.
JavaScript for example is interpreted. This in the long run speeds up (the website) as it doesn’t need to be compiled to various different devices’ machine code requirements, and each device can interpret the source JavaScript in the way that works for that processor. It also reduces network traffic as binary files may be much larger than compact source code equivalents.
- Compiled code executes faster than interpreted code as it is directly executed by the processor
- Compilers can apply optimisations during compilation for the program to execute more efficiently
- Once compiled, the code can then be distributed and executed on different devices providing they have the same processor instruction set, e.g exe files on windows x86 processors.
–
- Interpeters allow for better debugging capabilities and errors are detected at runtime for quick fixing
- Faster development cycles as recompilation which can take a long time is not needed
Bytecode
Most languages now use a combination of both compilation and interpreting.
Java is compiled into bytecode, which is an intermediate step between source code and machine code. The Java virtual machine interprets the bytecode, allowing for platform independence, as long as the JVM is installed. The JVM will be able to ‘customise’ the machine code produced to the specific processor.
Source -> Compiler -> Bytecode -> Bytecode interpreter -> Object code
Stages of compilation
Lexical analysis
Removes unnecessary spaces and comments
Keywords, constants and identifiers are replaced with tokens that represent their function within the program (tokenisation)
The symbol table
The lexer builds up a symbol table for every token in the program, which keeps track of the runtime memory address and value for each identifier. The table may include
- Canonical item name (e.g
userCoinsAmount,=) - Kind of item (e.g.
variable,operator) - Type of item (
float) - Value (
48.3061)
Syntax analysis
After the lexing stage, the tokens are now split up into phrases (e.g. a line of code), which is then parsed. During parsing, the language’s rules are applied to each phrase to determine if it is valid. An error will be thrown if the phrase violates the language rules (e.g. print("hello, world))
this is similar to a natural language!
Semantic analysis
A set of tokens may be valid syntaxically but not valid programatically. Semantic analysis checks for this error. This typically occurs at the same time as syntax analysis. Errors in this stage may be trying to assign an integer value to a real (floating point) variable in a statically typed language.
Code generation and optimisation
Programmers are lazy so often source code is inefficient. Code optimisation removes redundant instructions and replace inefficient code with code that achieves the same result. For example
i = 0
for count = 0 to 10000
x = 0
i = i + 5
endfor
print(x)
print(i)
Over several passes, code optimisation techniques may remove the for loop and just set x to 0 outside of the loop so that it doesn’t get redefined 10,000 times. More severe optimisations may calculate that i will be 50000 every time, so just change the value of y to 50000.
Linkers and loaders
The linker must assign memory addresses to external calls from separate libraries or functions so that the modules are linked correctly.
The loader must copy the program and any linked libraries into main memory to be executed. The loader will also correctly assign memory addresses, as the program expects that it is in memory address 0.
Libraries, pre-compiled code modules, have benefits such as being tested, optimised and save time as code does not have to be rewritten. It can also save on memory - many programs may use a library to set all characters to uppercase which only has to be loaded once into memory, and just linked by the linker, as opposed to redefining this every time.
1.2.4 Types of Programming Language
Assembly language
The Little Man Computer or LMC instruction set is a simplification of assembly language which has many of the same principals of the lower-level language.
Here is the assembly code which you need to know:
| Mnemonic | Instruction | Explanation |
|---|---|---|
ADD |
Add | Adds the value from a specific memory address to the accumulator |
SUB |
Subtract | Subtract value from a specific memory address from the accumulator. |
STA |
Store | Stores the value of the accumulator to a specific memory address |
LDA |
Load (Data Address) | Loads, into the accumulator, the data at a specific data address |
BRA |
Branch, always | Unconditionally branch or jump to a specific instruction |
BRZ |
Branch, if zero | Branch or jump to a specific instruction if previous operation resulted in zero |
BRP |
Branch, if positive | Branch or jump to a specific instruction if the previous instruction resulted in a postitive value |
INP |
Input | Takes an input from an external source and loads to the accumulator |
OUT |
Output | Outputs value of the accumulator |
HLT |
End program (HALT) | Halt or stop execution of program |
DAT |
Data location | Defines memory location and its value |
This can be used in any way to perform operations like adding adddresses in memory, squaring numbers, etc. You’ll need to be familiar with this and be able to spot errors and rewrite the instruction list when needed.
Modes of addressing memory
OO languages
Classes
Objects
Methods
Attributes
Inheritance
Encapsulation
Polymorphism
[tbd] 1.3 Exchanging data
Data and all sorts of information is constantly being moved, updates and transferred within a computer system or between (several) networks. Although nowadays data transfer and storage is extremely high-speed and accurate.
Large web hosting platforms like Google Cloud and AWS offer “five nines” uptime, 99.999%, meaning that every year, their services can only be down for a maximum of 5 minutes and 13 seconds. Some services have even higher uptimes, like six nines (reminds me of my GCSE results) or even eight nines - that’s 310 milliseconds of downtime per year.
To ensure this, data must be transferred and stored securely and be error-resistant. For global networks such as Cloudflare with over 200 datacentres, transfer is slower and more susceptible to interference with increasing distance, so how are these extremely low error rates possible?
1.3.1 Compression, Encryption and Hashing

Compression techniques
Text, videos, images, sound and all sorts of media can be reduced in size. The benefits of this include faster file transfer times, less bandwidth is used, less storage is needed by the client and server and user experience is better, with less buffering on YouTube streams, for example.
There are two types of compression:
Lossy compression
Non-essential information is removed from the source file. In the below images, the scene is clearly identifiable and if you open them in a new tab, you’ll be able to zoom in to fine details such as the house or trees in the background with some clarity.
If a pixel in an image is combined with a block of others in lossy compression, it isn’t much of a deal.

Directly from my phone camera. 25.438 KiB

Compressed! 543 KiB. ~50x reduction in filesize
However, with the second image here, you should be able to tell that it’s not as clear or as precise as the first one. Different colours have been merged into one, and “blockiness” is visible as the compression algorithm tries to combine multiple areas that have generally the same colours into one to save storage space. It tries to remove as much of the less significant details as possible, conserving the general essence of the image. There is a trade off between how heavily the image is compressed (and therefore the smaller the filesize) and the quality.
Real life example: I run iBaguette.com. On the main site, I was using 1080p PNG images straight out of Photoshop for the article thumbnails. I switched to using lossy compression, and it reduced the file size by 95% at almost no visual quality loss as they are relatively small on the page, especially on mobile devices. With 5 articles loading, this sped up the page load times by ~2 seconds.
This logic can be applied to audio too. MP3 files and OGG files are formats that use lossy compression to remove sounds ouside of audible hearing ranges, or by removing quieter elements of a music track that play at the same time as louder parts.
VoIP services like Discord use compression at various bitrates to transmit peoples’ voices. Lower bitrates such as 8kbps will require more compression and people will sound less defined and monotonic, while higher bitrates such as 64kbps - the default by many services today - will not have any issue in understanding the person at the other end of the line as this is less compressed. However, humans can still discern the difference between even the highest bitrates and being face-to-face.
With advancements in audio codecs and compression techniques, lower bitrates have become more usable.
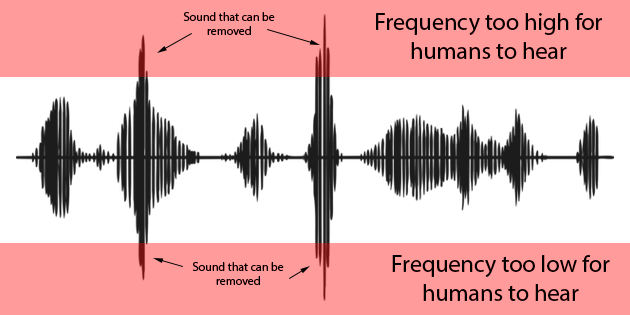
Visualisation of what happens to audio content
Lossy Compression:
| Advantages | Disadvantages |
|---|---|
| Small file sizes vs the original and vs lossless | Quality can be reduced significantly |
| Very fast data transfer and load time, suitable for websites | Not suitable for more precise applications |
| Lower processing power to decode | Original data cannot be fully recovered; irreversible |
| Widely supported and popular across platforms and devices |
Lossless compression
Lossless compression techniques records and optimises patterns in the source data, rather than changing the data itself. As a result, when this losslessly compressed file is transferred, it can be decompressed in a way that is structurally identical to the source file, even though the data may not be represented identically to the source file during transfer.
It uses algorithms to encode the source data in a more efficient way.
Lossless compression is important when transferring files such as binary data (like program files for OS updates) or when conserving all original content. This is because if a bit is lost in machine code, it could result in a critical error.
- WAV and FLAC files are examples of lossless audio containers and codecs, respectfully.
- PNG and RAW image files are lossless
- ZIP files can contain any number of file, in a losslessly encoded manner
However, lossless compression has disadvantages too. Lossy files are still much better for highly optimising size and quality of images as they are able to discard large amounts of the file if needed. Therefore, generally, only slight reductions over the initial file are possible.
Lossless compression:
| Advantages | Disadvantages |
|---|---|
| All of the original file’s data is preserved | Longer file transfer times and potential buffering |
| Smaller file sizes compared to original | Sometimes unnecessary, e.g. for website images |
| Good for archival storage, or for high-value files | Still much larger file size than using lossy techniques |
| Preserves fine and intricate details of music, videos and images | Can occupy large amounts of drive space for diminishing quality returns |
| Inneffective for more random data - may be larger than the original file | |
| Compression algorithms require more computing resources to compress and to decode |
There is no universal right/wrong option for which compression technique to use. It is a matter of trade-off between saving storage space, loading times, quality and type of file.
Run length encoding (RLE)
Run Length Encoding is a lossless data compression algorithm. It replaces repeated, consecutive patterns of the same data with a “summary” - an instance of that specific element, as well as a count of it.
RLE works well where there are consecutive, repeated elements. This could be pixels in an image, musical notes or binary data. Here’s an example:
AAAAABBBCDDAAA -> 5A3B1C2D3A.
To decode this data, the sequence just has to be expanded using the counts, and the source sequence will be reconstructed.
Likewise, if there are 10 adjacent pixels in an image with the same colour “00000110”, this could be represented in RLE as 10(00000110).
Dictionary encoding
Dictionary encoding finds data which occurs regularly in a source file, and adds suitable matching data to a dictionary. This is like a table, with a numerical value, its data and a binary representation. The phrase “no_pain_no_gain” can be added to a table such as:
| Number | Data | Binary |
|---|---|---|
| 1 | no_ | 00 |
| 2 | p | 01 |
| 3 | g | 10 |
| 4 | ain_ | 11 |
Assuming zero overhead and optimal implementation, “no_pain_no_gain” goes from 15 bytes to:
000111001011 (12 bits)
However, for tiny strings like this, using a dictionary is impractical as the amount of data needed to create the dictionary would be larger than the savings from using it. However, if both the sender and receiver have the same existing copy of a dictionary and reference this, or create a dictionary for a large corpus of text like a book, then the potential savings are extremely high.
LZMA compression (Lempel-Ziv-Markov chain algorithm) is a popular lossless open-source algorithm that uses dictionary encoding. Zip and gzip use variations of this algorithm.
Encryption
Encryption is a method of transforming data from plaintext in a way such that it cannot be understood by people who do not have the means or authority to decrypt it.
- Original message is plaintext.
- Encrypted message is the ciphertext.
- Encryption method/algorithm is the cipher.
- Data required to decrypt a message is the key (decryption key).
Plaintext -> cipher -> ciphertext -> key -> plaintext.
The Caesar cipher shifts letters of the alphabet by a fixed amount. It is a substitution cipher.
However, it is easily decrypted (or “cracked”) by using little or no computing power. This can be done through a brute force attack, which uses every possible key to decrypt ciphertext until one works. To combat this, spaces are used to hide lengths of individual words. As there are only 26 characters in the alphabet, this is easily brute forced.
Vernam cipher/one-time pad
This was invented in 1917 and is the only encryption method still proven to be unbreakable.
It consists of a few key features:
- The cipher or one-time pad must be equal or longer to the plaintext.
- The cipher/one-time pad must also be truly random.
- Both parties must physically meet to exchange the cipher.
- The cipher can only be used once; destroyed after use.
To actually encrypt the data, the bitwise exclusive OR operator (represented as ^ or XOR) is used on all plaintext with the corresponding character number in the key, after having translated all characters into the binary ASCII equivalent
This rule states that:
- 0 and 0 will output 0
- only 0 and 1, or 1 and 0 will output 1
- 1 and 1 will output 0.
This could look like :
Plaintext char: 0100 0010 (B)
Corresponding cipher char: 1110 0010 (Γ)
| ASCII representation | Cipher | XOR |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 1 | 0 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
| 0 | 0 | 0 |
| 0 | 0 | 0 |
| 1 | 1 | 0 |
| 0 | 0 | 0 |
= 1010 0000. (this is á.)
As this typically occurs in binary, unprintable characters are often produced such as
\x9F(Control).
To decrypt it back to plaintext, we XOR the result and the OTP.
Result of the original XOR (ciphertext): 1010 0000 (á)
OTP: 1110 0010 (Γ)
^ = 0100 0010 (B)
This also beats cryptanalysis techniques as methods such as frequency analysis attacks - which rely on comparing the frequency of letters in cyphertext to how often these letters appear in general communication - as each character of the ciphertext is truly random. This is referred to as entropy - unpredictability in cryptography.
In cryptography, random does not just mean statistically random - it also means unpredictable.
Methods of generating real-world randomness include lava lamps (see image below), a double-pendulum system or radioactive decay.

An example of how entropy is created using lava lamps in the Cloudflare HQ. Click here for further reading.
Symmetric (private key) encryption
This uses the same key to encrypt and decrypt information. Think about an encrypted zip file - you add the password at the start, send the password (the key) to someone else (this is key exchange) and they can decrypt and unzip it. If the key is intercepted at all during transmission, it can compromise the security of all past and future communications which have used the same key.
Asymmetric (public key) encryption
Asymmetric encryption uses two different but cryptographically related keys. The public key is made public, so all people wanting to send an encrypted message to the private key holder are able to do so. The private key is kept secure by typically one user or entity, and this key can then decrypt the data encrypted by the public key. This key cannot be deduced from the public key.
However, an intercepted message could be encrypted using your own public key impersonating a sender. To prevent this, digital message signing certificates can be used, which employs similar principals.
Hashing
A hash function is an irreversible function to go from an input of arbitrary length to a fixed-length output.
This is typically used when storing passwords. Even if the database of user accounts and passwords is compromised, the hashes of these passwords are useless as they are one-way - will only match when the user enters the same password. Unless it’s not already on a list of known hash digests…
Known lists of hashes and their original values are called “rainbow tables”.
SHA256 is an example of using a hash function. It can take any data as an input - a video file, checksums, text, and return a 256 bit string.
Even if 1 bit of input data is changed, these functions will return completely different results. This makes them useful as checksums in packet headers, or for validating that a file has been downloaded correctly.
Salting is an additional method of securing data by adding a unique random value to each password before hashing it, resulting in a cryptographically different hash value, theoretically immune to known hashes, even if the password is “password123”.
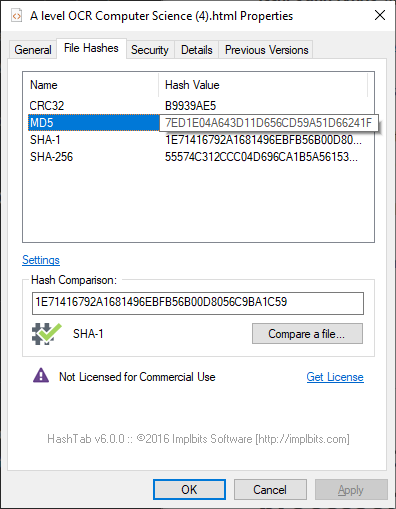
The SHA-1, CRC32, MD5 and SHA-256 hashes for this file at the time of writing. Oops, as I’ve written that, it’s changed already…
“1E71416792A1681496EBFB56B00D8056C9BA1C59” - sha-1 hash
Uses for hashing
Hashes are used in packet headers (checksums), digital signatures to prove identity, digital certificates and Public Key Infrastructure (PKI) and more.
1.3.2 Databases

I really don’t like databases. They are just boring. But luckily they’re easy to understand and remember once you’ve got your head around them.
Database concepts
Firstly, entities need to be worked out.
An entity is a category of object, person, event or thing of interest about which data is needed to be recorded.
For example, employees of a company, films, actors, club members. Each entity has attributes.
The simplest kind of database, a flat file, holds data about one entity only, such as a user’s coins and roles in the Baguette Brigaders Discord Server.
If you are designing a system for a company that sells subscriptions for online revision resources, a flat file would not be useful.
luckily here at iBaguette we don’t sell anything or lock anything behind a paywall.
There would need to be a few entities in this scenario, all linked together
- Customer
- Customer Name
- Customer Surname
- Revision product
- Subscription
- Order number
- Subject
- Tier of revision guide
- more?
The DBMS (Database management system) needs to have a unique identifier for the entity. The primary key is notated by being underlined. It is automatically indexed.
Two or more attributes that are needed to uniquely identify a record are composite primary keys.
User (customerID, orderNumber, custName, custSurname, productID, subject, tier)
Searches may also need to be made on other attributes of entities. In the table above, subject, tier, productID, custName and custSurname can be definded as the secondary key. These would then be indexed if specified by the user.
Entity relationship modelling
An entity relationship diagram is a way of representing the relationships between entities within a database. These can be:
- One-to-one: husband to wife, country and prime minister. There is only one possiblility of a relationship between either entity
- One-to-many: mother and child, customer and order, country and residents. One of these entities has many relationships between related entities
- Many-to-many: actor and film, pupil and schools. Many of these entities have relationships between many other entities.
Individual E-R diagrams may be joined up, to effectively say for the example above:
Customer -> one-to-many -> Subscription -> many-to-one -> Product.
Foreign and Composite Keys
Each entity must have a primary key as an attribute. In a relational database, to create a relationship between two entities in a one-to-many relationship, we need to include an attribute about the first entity (we’ll say Customer) in the table of the second entity (we’ll say Subscription). This second entity table must uniquely refer to the first entity, so we will include Customer’s primary key in Subscription’s table. This is known as the foreign key for Subscription.
Customer in this table can be thought of as a class - it inherits attributes about it from a blueprint. However it needs to be unique, so primary key CustID will need to be assigned to it. This is the same for SubscriptionID - but SubscriptionID is not needed in the attributes of the Customer, as the database may be searched for CustomerIDs in the Subscription table.
Referential Integrity
Referential integrity states that an attribute referenced as a foreign key on one table cannot be deleted, and therefore cannot reference something that doesn’t exist. For example adding customerID 193 in table Subscription should not be possible if there is no customerID 193 anyway.
Normalisation
In a relational database, data is held in tables, or relations. Each row in the table holds a specific, unique record, with each column representing an attribute.
| CustID | SubID | prodID | Tier | custName |
|---|---|---|---|---|
| 12 | 120.CmpSc | 235 | 4 | Jake |
| 34 | 111.Geog | 243 | 2 | Kez |
| 54 | 120.CmpSc | 235 | 3 | Frankie |
| 54 | 121.French | 239 | 5 | Oli |
Normalisation is a process used to create the most efficient design possible for a database. The structure should be one so that complex queries from different relations can be made, with no unnecessary duplication and high consistency.
First normal form
A table is in 1NF if it has no repeating attributes, or groups of attributes.
All attributes must be atomic, so one atribute must only contain data about one thing, not two items of data such as firstname and surname - this would make the relation unable to be queried by surname or firstname alone.
Second normal form
A table is in 2NF if it:
- Is already in 1NF
- Has no partial dependenies, which is only so if the primary key is also a composite key.
This means that if any non-key column is only dependent on one primary key but not them all (hence why it is only applicable to composite keys) it exhibits a partial key dependence.
For example, a table may have a composite primary key of OrderID and ProductID, but a non-key column “OrderDate” depends only on OrderID and not ProductID, it is partially dependent.
Third normal form
A table is in 3NF if it:
- Is already in 2NF
- Has no transitive, or non-key dependencies.
All attributes are dependent on the key, the whole key, and nothing but the key.
This means that if non-key columns are dependent on something other than the primary key (e.g. are foreign keys that relate to the primary key of another entity) they have to go. If a table is such that:
Component(ComponentID, ComponentName, SupplierID)
it can be seen that SupplierID is a foreign key and does not depend on the ComponentID of the Component entity, rather a different entity. It will then be moved to a separate table, with all dependent columns moving to this new table.
Importance of normalisation
There are benefits for carrying out normalisation on databases and tables. These include:
- Easier to maintain
- Easier to query
- No data redundancy
- Data integrity is maintained
- Faster sorting and searching
- No accidental deletion of records
SQL
SQL stands for Structured Query Language. It is the backbone of most major database querying languages; you’ve probably used a service today that uses this language for database management
Basic Select
SELECT Fields
FROM TableName
WHERE (value CONDITION value)
ORDER BY Field ASC
Conditions
| Condition | Description |
|---|---|
| = | Equal to |
| > | Greater than |
| < | Less than |
| IN | In a set of values |
| LIKE | Pattern matching |
| BETWEEN… AND… | Between a range of values (inclusive) |
| IS NULL | Checks if a value is NULL |
| AND | Logical AND operator |
| OR | Logical OR operator |
| NOT | Logical NOT operator |
Detailed Select
You can extract data from specific and multiple tables using . - for example:
SELECT Song.SongTitle, Song.ArtistSurname, Artist.ArtistSurname
FROM Song, Artist
WHERE (Song.SongTitle LIKE "R%") AND (Song.ArtistSurname = Artist.ArtistSurname)
Defining a database table
To create a table, the CREATE TABLE keyword
CREATE TABLE Film
(
FilmID INTEGER NOT NULL, PRIMARY KEY,
Description VARCHAR(20) NOT NULL,
ReleaseDate DATE,
LastShownTime TIME,
IsShowing BOOLEAN NOT NULL,
ShowingCount INTEGER
)
Altering a table
To alter a table, we just use ALTER TABLE. This is used to add, delete or modify fields or columns.
ALTER TABLE Film
ADD Cost FLOAT(3,2)
ADD Name VARCHAR(20) NOT NULL
DROP COLUMN ReleaseDate
MODIFY COLUMN Description VARCHAR(35) NOT NULL
Linking tables
Of course, we need to link several tables! This is done by foreign keys
CREATE TABLE NewFilm
(
FilmID INTEGER NOT NULL,
Name VARCHAR(20) NOT NULL,
ShowingID INTEGER,
Description VARCHAR(35) NOT NULL,
ReleaseDate DATE,
FOREIGN KEY ShowingID REFERENCES ShownFilms(FilmID)
FOREIGN KEY FilmID REFERENCES Films(FilmID)
PRIMARY KEY (FilmID, ShowingID)
)
Phew, that looks complicated…
Inserting values
We use INSERT INTO, followed by the VALUES that we want
INSERT INTO NewFilm(FilmID, Name, ReleaseDate)
VALUES ("1223", "Spider-Man, Across the Spider-Verse", #02/06/2023#)
Updating
Simple! Just UPDATE the table, SET the values WHERE a condition is met.
UPDATE Film
SET Showing = Showing + 1
WHERE FilmID = "1337"
Deleting
Just DELETE FROM a table WHERE a value is met
DELETE FROM NewFilm
WHERE ReleaseDate = "02/06/2023"
Transaction Processing and ACID
Atomicity
A transaction must be processed in its entirety or not at all. It is not possible to process only part of a transaction no matter how catastrophic the failure is.
Consistency
No transaction can violate the defined validation rules. Referential integrity will always be upheld.
Isolation
The concurrent execution and processing of transactions must be the same as if these transactions were processed sequentially.
Durability
A transaction will always remain committed once a it has been made.
This is undertaken by having a buffer, either in the disk or in memory, which receives the temporary modifications. Once all of the transactions have been made, only then will it be committed and written to the disk.
Problems with multi-user databases
If user A wants to chnage user X address, this is fine. If two minutes later, user B changes user X’s balance and saves the record, this is fine. However when user A saves the new record with just the updated address, user B’s changes are lost. To prevent this, we can use:
Record locking
To uphold ACID, if two users are editing a database and want to edit each other’s attributes, they may lock each other’s records and result in deadlock. The DBMS will recognise this and try and use one of the below things to fix it:
Serialisation
Serialisation, in database management systems, is the principal that transactions cannot start until the previous one has ended. This can be done by:
Timestamp ordering
Assigns every object in the database a read and write timestamp, so it can be worked out which transaction took place first and be applied first. Two users editing the same file at the same time could be asked to merge changes when they have finished by the other user, reducing the rick of problems
Committment ordering
Transactions are ordered depending on how much they rely on each other, as well as time they were initiated. These subsequent modification requests can then be blocked until the initial transaction is committed.
Redundancy
There may be multiple systems available in different physical locations which can be switched to if there is an error in one DBMS. This is crucial in busy businesses or where there is a lot of information that is of high importance being transferred and updated simultaneously.
1.3.3 Networks

The Internet is a public interconnection of computer networks which allows data to be sent to any connected device, globally.
The World Wide Web is a collection of websites and documents linked by hyperlinks made accessible via the Internet.
The Internet is the largest network (what computers communicate with each other on). THis is known as a Wide Area Network, or WAN, as it spans over a large geographic area.
The Internet can also be used to transmit data without using the World Wide Web. However, this data must travel through the backbone.
The Internet backbone is the core infrastructure of the Internet. It is made up of a series of dedicated, high-transmission fibre-optic cables that ‘peer’ (are connected with) each other, and are owned by large Internet Service Providers (ISPs).
By connecting all these cables together, these ISPs can create a single network that gives each other access to the entire Internet. The way they communicate is by using the TCP (Transport Control Protocol) and IP (Internet Protocol) protocols.
Protocol - a set of rules or procedures for transmitting data between electronic devices, such as computers
IPv4 addressses
are a series of 4 octet values separated by a full stop (max 32 bits), ranging from 0 to 255. However, there are not enough addresses to support the growing population, so IPv6 is being used which uses 128 bits.
Uniform Resource Locator (URL)
URLs are a standardised format for specifying the means of accessing a resource on the Internet and identifying its location. A URL consists of many components, including the protocol, domain name and path to the specific resource.
The protocol (like HTTP, HTTPS, FTP or WSS) indicated the communication method to access the specified resource. If it is using HTTP/HTTPS, then the resource is going to be on the World Wide Web.
The domain name (like ibaguette.com) identifies the server where the resource is hosted.
By using URLs, users can easily access resources such as web pages, images, documents, and other files on the internet.
Domain Name System (DNS)
The Domain Name System is a distributed database system that enables the translation of domain names into IP addresses, which can then be used to contact a server.
DNS servers are therefore dedicated computers that store an index of domain names and their corresponding IP addresses.
When a user types a domain name into their web browser or other application, the application sends a request to a DNS server to resolve the domain name to its associated IP address. The DNS server then searches its index for the domain name and returns the corresponding IP address to the requesting application. This allows the application to establish a connection to the server associated with the domain name, enabling the transfer of data between the client and server.
Frequent DNS queries are often cached on a client’s system so that a DNS server does not have to be contacted every time, and instead read from a DNS cache stored by the operating system or browser cache, which is much faster.
If the local DNS server does not have a record for the domain, it may forward the request to an ISP’s DNS server. If the ISP DNS server does not have a record, then it may be forwarded to one of 13 global root DNS servers which hold the records of every domain on the Internet.
This process is known as recursion and enables the DNS system to efficiently resolve domain names to their corresponding IP addresses, even for domains hosted on remote servers.
Below the root servers are generic and country top-level domains (TLDs), such as .com, .edu, .org and .uk, .fr and .de.
Internet registries
Domain names must be completely unique otherwise DNS requests could be manipulated. There are 5 global Internet registries (RIRs) which are responsible for allocating IP addresses to organisations in their respective regions (typically continental).
IANA (Internet Assigned Numbers Authority) is responsible for coordinating the allocation of IP addresses to the RIRs.
Area Networks
In a Local Area Network two, or more, computers are connected together, physically using a ethernet cable or wirelessly, within a small geographical area. For instance, within a small office or school site which is mostly confined to one building or site.
Hubs and switches
A network switch is a hardware device that is commonly used to connect various network segments within a LAN. Switches are designed to forward data packets between different devices on a network.
Unlike hubs, which broadcast data packets to all devices on a network segment, switches selectively forward data packets only to their intended destination device.
Hubs connect multiple Ethernet devices together, making them act as a single network segment. Hubs are an older type of connector and are less commonly used today due to their limitations. Unlike switches, hubs broadcast all data packets to every device on the network, which can lead to network congestion and reduced performance.
A network switch operates by learning the MAC addresses of devices connected to it, and then using this information to forward data packets to the appropriate device. This allows devices on the network to communicate with one another directly, without the need for every device to receive every packet.
Watch out! Many people still use the word ‘hub’ when they mean ‘switch’!
Physical network topologies
A network topology refers to the physical or logical arrangement of computing devices which make up a network.
Bus topology: an arrangement where nodes are connected in a ‘chain’ by a single central communications channel, or ‘bus’. Each end of this bussy backbone is connected to a terminator which stops signals bouncing back. Each terminal, or node, on this cable is passive.
They are simple to set up and cheap, but only one computer can transmit data successfully at a time (or “collisions” will occur) and there is poor security generally, with a single point of failure, as well as being unsuitable for larger areas.
Star topology: an arrangement where a central node or switch (or hub) provides a central point of communication for all other nodes. A device connected to this network can send an appropriate message to the switch, which then uses both devices’ Media Access Control (MAC) address to determine where to send the message.
The failure of any one device (unless it is the switch itself) does not affect the operation of the network as a whole. This makes star networks highly reliable and easy to maintain, as well as being easy to add new stations. Higher transmission speeds can give better performance than a bus network too.
Star networks are a popular choice for LANs and other small-scale networks, due to their simplicity and reliability. They are especially well-suited for networks that require high bandwidth and low latency and as well as for security, as data is sent only to one other device.
Logical network topologies
-
The physical topology of a network defines how the devices are physically connected.
-
The logical topology defines how the devices communicate across the physical topologies.
For example, a network might be physically wired in a star topology, but use a logical bus topology to facilitate data transmission.
Wi-Fi is a wireless networking technology providing high-speed Internet and network connections. Devices connect to the Internet via a Wireless Access Point (WAP) which broadcasts on a specific radio frequency channel, typically on the 2.4GHZ spectrum or the 5-6GHz spectrum. This can then be accessed by any device within range and that has a compatible Network Interface Card (NIC).
However, network interference from other devices within range which are also using the same frequency is problematic, as seen in areas like football stadiums. To minimise this, admins can use channel bonding to pool multiple channels into a wider band, thereby increasing available bandwidth, and using Quality of Service (QoS) which prioritises different types of network traffic based on their importance, such as VoIP calls which require low latency.
Mesh networks
Mesh networks are becoming more common with the widespread use of wireless technology. Each node in a mesh network has a connection to every other node, by transmitting data across any intermediate nodes, and only one node needs an Internet connection and all other nodes can share this, creating a redundant and flexible network architecture. These networks can become big enough to cover entire cities.
| Advantages | Disadvantages |
|---|---|
| No cabling costs: mesh networks can be wireless | Higher implementation and maintenance costs, especially for smaller businesses with limited resources |
| Network scaling and setup can be easier without added cabling allowing for easy expansion, as new nodes are automatically added to the network | Redundant connections can add to costs and complexity of the network, requiring increased planning and network management |
| Self-healing: with more nodes, the faster and more reliable the network becomes (one blocked route can just use other routes) |
Packets, Packet Switching and Routers
Packet switching requires routers to direct the packets to their destination. A router is a network device that receives packets and forwards data packets from one network to another.
Each router stores data about the available routes to the destination node. It looks up the destination IP address in its routing table to find the best router to forward the packet to.
Each transfer between routers is known as a hop
Routers will then continue to forward the packet until it reaches its destination node.
A packet is a segment of data that needs to be sent. They are made up of the trailer, payload and header.
Packets are deliberately kept small to ensure that individual packets do not take excessive time to transfer preventing other packets from moving.
However, they should not be too small as the additional data added makes data transfer inefficient as unnecessary headers and trailers would be required each time.
The trailer contains the end of packet flag, as well as error checking components like checksums or Cyclical Redundancy Checks (CRCs), are calculated at the origin and destination end. If they do not match, the data has become corrupted and is refused and a new copy is requested to be sent again.
The payload is the actual data that needs to be sent, varying in size from 500 to 1,500 bytes.
The packet header contains the IP addresses of the recipient and the sender, so that it can be directed appropriately across the network. The packet number and overall number of packets in the transmission is attached to assist in reassembling the data at the receiving end. The Time to Live (TTL), or hop limit, is also included.
This is all dictated by the Transmission Control Protocol (TCP).
Circuit switching
On the other hand, circuit switching is a communication method in which a dedicated physical path is established between two devices for the duration of the communication session, even when no data is being transmitted.
This doesn’t really work for the billions of devices that are connected. The complete circuit can’t be shared by other devices, so how would this work when downloading a 10gb file? You’d have to wait for the entire download to finish to start doing something else. This makes circuit switching only really useful for realtime scenarios like phone calls when a consistent and uninterrupted connection is required. (But, if one point in the circuit fails, the entire phone call will as data cannot be rerouted, unlike packet switching)
In summary, packet switching divides data into packets and transmits them over the network to their destination, where they are reassembled. Packet switching is more efficient and flexible than circuit switching, and is thus more widely used.
Protocols and Standards
Network hardware devices include routers, switches, hubs, and access points, among others. These devices connect computers and other devices in a network, allowing them to communicate and share resources.
Protocols and standards establish guidelines and rules for communication between devices on a network. Common protocols include TCP/IP, HTTP, and FTP, while common standards include Ethernet and Wi-Fi.
[tbd] The TCP/IP Protocol Stack
The TCP/IP protocol stack consists of four main layers. From the top of the stack to the bottom, they are:
Application layer
It specifies what high-level protocol needs to be used in order for applications to communicate with each other over a network.
- For example, if the application is a browser then it would select a protocol such as HTTP
- Email clients would use SMTP and POP3/IMAP
- File transfer programs may use FTP.
This specifies the rules of what should be sent, rather than the actual data/payload.
Transport layer
The transport layer uses the Transmission Control Protocol (TCP) as well as the User Datagram Protocol (UDP) to establish an end-to-end connection to the recipient.
Application data from the above application layer often has large filesizes, such as uploading a 10GB video file, and thus must be split into segments, or TCP packets, and then numbers these sequentially.
The port number (a 16 bit number) is also added in this layer. Servers listen on specific well-known port numbers like 443 for HTTPS for oncoming connections. On the client end, ephemeral port numbers are assigned so received data can be passed up from the transport layer to the application layer to the correct, unique application.
If there are 65,535 TCP connections or more at a time all accessing some data, new connections cannot be established as this is the 16-bit limit for the transport layer!
Finally, sockets, or TCP endpoints, are also assigned on this layer. These are made up of the IP address and the port number, such as 83.231.132.94:25565. These sockets are either the source or the destination, for example, accessing ibaguette.com will make the accessor (client) the source, and the server’s port 443 will be the destination, and send the data to the client. The destination and source ports on the server and client will then swap.
Sockets can be combined with DNS to go to a specific port on a website. For example, mc.ibaguette.com:8123 could initiate a HTTP connection to a server with a specific port of 8123 rather than the default HTTP port of 80.
Bonus Points for A*
TCP ensures that no data is received erroneously or is lost during transport, so packets can be retransmitted and all must me acknowledged by the receiving device. This security adds delays and additional processing overhead. UDP does not add any of these error checks, but is more suited towards realtime applications such as Discord Voice Chats, whereas text chat it uses TCP.
For this reason, UDP is deemed as the unreliable protocol as it is “send and forget”, with packets arriving out of order or not at all. TCP is a sequential stream but is slower due to ACK packets (acknowledgement) and can cause packets to queue and ping spikes. TCP is susceptible to ping spikes, and UDP is susceptible to packet loss (hence why in online games you get packet loss and ping spikes - they use both depending on what’s being requested!)
Internet/Network layer
Uses the Internet Protocol to address packets with a destination and source IP address in each packet’s header. Other data fields in the header may include the Time To Live (TTL) or maximum packet hops, and the header checksum.
It’s worth noting that the IP has no guarantee of correct transmission, and it is up to TCP in the transport layer to do this.
Link layer
This is also known as the Data Link/Network Interface layer
Each layer has its own specific tasks in transmitting data over a network.
The link layer operates across a physical connection
Adds the MAC address of the physical NIC that packets should be sent to based on the destination IP address
MAC addresses change with each hoptasks in transmitting data over a network.
Transferring Files using FTP
FTP (File Transfer Protocol) is a standard protocol used to transfer files. It is widely used for uploading files to and downloading files from servers with little overhead.
Email Servers
An email server receives incoming messages and stores them until the recipient retrieves them. It also sends outgoing messages to the intended recipients. Email servers use various protocols such as SMTP, POP, and IMAP to transmit and receive email messages.
1.3.4 Web technologies

How to add an external stylesheet:
<link href="nameofstylesheet.css” rel=“stylesheet” type=“text/css”>
Changing the attributes of an HTML element:
// Get element with id "example" from the DOM
var chosenElement = document.getElementById("example");
// Change the displayed HTML content
chosenElement.innerHTML = "Hello, World!";
[tbd] 1.4 Data types, data structures and algorithms
This section is about how data is represented and stored within different structures, and how different algorithms can be applied to these structures.
Primitive data types, binary and hexadecimal
Primitive data types are those which are provided by a programming language. They are then stored by the computer in binary. They include:
- integers (whole numbers, both negative and positive)
- strings (anything represented as text, typically through “quotation marks”)
- Boolean values (
TrueorFalsevalues) - floating points (or reals, which are numbers with a fraction/decimal)
- characters (singular characters in a character set, which may be letters, numbers or special symbols)
To then represent these data types, varying number bases are used. Ultimately, computers must store the data in binary (a base 2 system), whilst strings such as colours can be represented in hexadecimal for simplicity, which is a base 16 number system. To show these number bases, subscripts are used. They look like this:
- 5310 - denary (base 10) value of 53
- 10012 - binary (base 2) value for 9
- 2316 - hexadecimal (base 16) value for 35
Converting between denary and binary
Converting between these bases is simple. Write out a table with 8 columns (bits) for a number up to 255. Then, label each column from left to right, doubling in value, starting at 1 and ending at 128. You will need to continue into the second byte if the number is 256 or greater.
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
This value is unsigned. Remember that for later.
Now, to calculate the number in denary, add up each column where the value is 1. For example here you would add 128, 32, 2 and 1 for a total of 163 in denary.
To go the other way, simply draw out this table again, and start from the most significant bit (left) side. Take your number and if it is greater or equal to the value of the column, add a 1 to the column and then subtract the value from your number, and move to the next least significant bit. Continue until your number is zero, where the remaining columns will be filled in with 0.
Hexadecimal conversions
Hexadecimal is slightly more tricky. The values of this base system are the same up until the denary value of 9 (1001), but anything above this will involve letters. The value of 1111 (15) in hex is F.
To convert from binary to hex, split the binary into nibbles (groups of 4 bits). From this, simply write the hex conversion table and write each character (0-9, A-F) for each nibble.
To convert the other way, do this in reverse. To do this mentally, remember that F is 1111 and 9 is 1001: it is relatively easy to calculate each hex value from these two points.
Converting hexadecimal to denary is also easy. If there are 2 (or more) hex digits, remember that the most significant bit row represents the number of 16s (in denary) that go into that number. As such, if the hex value is CF, then remember that C is the denary value of 12. However, this must be multiplied by 16, as this column represents the number of 16s due to the number base, so 16x12 is 192. Then, add the value of F, which is 15, to give the value of 207.
Finally, converting denary to hexadecimal can be more tricky. A quick way to do this is to DIVide the denary number by 16 for the most significant bit column, and get the remainder (MOD) for the lesser significant bit.
For example, to work out the hex of 175, you would do:
- 175 DIV 16 = 10
- 175 MOD 16 = 15
10 in hex is A (1010)
15 in hex is F (1111)
The answer would be AF
Binary arithmetic
When adding or subtractiing binary numbers, go from the least to most significant bit. Always remember that:
- 0 + 0 = 0
- 1 + 0 = 1
- 1 + 1 = 0 (and carry 1)
- 1 + 1 + 1 = 1 (and carry 1)
Negative binary and two’s complement
Sign and magnitude
To represent negative numbers, the most common method used is to use the most significant bit as the sign bit. When this leftmost bit is 0, represents a positive number, and when 1 represents a negative number. This is known as the sign and magnitude representation method.
The positive binary value of 00010001 (19) can be used to work out the negative value 10010001.
However, when performing arithmetic operations on this, it doesn’t really work. Therefore, we use two’s complement instead of sign and magnitude.
Two’s complement representation
Two’s complement is a way to represent both positive and negative numbers in a way to easily facilitate arithmetic operations on them, by making the most significant bit a sign bit which denotes whether the binary value is positive or negative.
Where the most significant bit is the sign bit, the value is one which is signed.
To calculate two’s complement, firstly invert all bits that represent a binary number. This means making all 0s 1s, and vice versa. The result is a value known as one’s complement. Then, add the binary value 1 to one’s complement. The resulting value is the negative (or positive, depending on the chosen number) equivalent of the number inputted.
Here is an example of how to convert negative denary to binary for an 8-bit system:
- 19
= 0001 0011
= 1110 1100 (one’s complement)
= 1110 1101 (two’s complement)
Similarly, to convert a negative two’s complement binary value to denary:
1011 0000
= 0100 1111 (one’s complement)
= 0101 0000 (two’s complement - we are adding 1 in binary, so carries apply)
= 64+16 = 80
= -80 (the original value’s sign bit was 1, so this final value is also negative)
When subtracting, we can also use this:
- 27 - 8 (this is equivalent to 27 + (-8))
- 27 is
0001 1011 - 8 is
0000 1000
- 27 is
- Now, calculate two’s complement of 8:
1111 01111111 1000
- Now, time to add the values:
0001 10111111 1000(1) 0001 0011
Therefore, the final value is 0001 0011, which is 16 + 2 + 1 = 19. This is indeed 27-8. The overflow digit is ignored: if it wasn’t, the value would be negative 19.
Arithmetic operations with decimals
Of course, when representing numbers, decimals and fractions also are part of the overall equation.
When using decimals on a traditional binary number line, we can extend this to the right below the value of 1. From left to right, the value of the number line halves each time, and this is continued with values below 1. To show these, we insert a binary decimal point and the values to the right of it will represent 0.5, 0.25, 0.125, 0.0625 and so on.
For fixed-point binary numbers, there is a given number of bits before and after the decimal point.
When representing fractional/decimal denary values in binary, it’s as easy as the conversion of denary to binary earlier, with an added bit for fractions. For example:
Number: 25.875
- 25 in binary:
0001 1001 - 0.875 in binary:
0.111 - Answer =
00011001.111- This can be simplified to
1100 1.111for 8 bits. The leading zeroes can be truncated
- This can be simplified to
Some numbers with decimals will never be accurately stored. An infinite level of precision will be required to represent numbers, using inverse powers of 2, such as 0.1 and 0.2. For example, 2/3 would be 0.1010101010…
Floating point arithmetic
Floating point binary numbers allow the
[tbd] 1.5 Legal, moral, cultural and ethical issues
The Data Protection Act 2018 controls the way data about living people is stored and processed
- It is a national law which complements the European Union’s General Data Protection Regulation (GDPR)
The Computer Misuse Act 1990 makes it an offence to access or modify computer material without permission
The Copyright, Designs and Patents Act 1988 covers the copying or use of other people’s work
The Regulation of Investigatory Powers Act 2000 regulates surveillance and investigation, and covers the interception of communications
Paper 2
Boolean algebra
Logic gates
There are a range of logic gates used in electronic components. These logic gates can take in one or more inputs, and produce a single output. This output can be used as the input of another logic gate and repeated to create a sophisticated and complex circut, such as the ones fonund in a CPU.
The four you need to know are NOT, AND, OR and XOR gates.
A truth table is a way of representing the inputs and outputs of logic gates in a tabular format. For a NOT gate, it would look like this.
NOT gates
Also known as negation.
Takes in one input and inverts it.
Looks like a triangle with a small circle on the end.
| Input A | Output Z |
|---|---|
| 0 | 1 |
| 1 | 0 |
The Boolean expression of a NOT gate is [tbd]
AND gates
Also known as conjunction.
As a boolean expression, this is written as N [tbd]
Both inputs must be True or 1 in order for the output to be True. Otherwise, the output will be 0
| Input A | Input B | Output Z |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
OR gates
Also known as disjunction. At least one input must be True for the output to be True.
XOR gates
Also known as exclusive disjunction.
There must be exactly one input which is True for the output to also be True.
Simplifying Boolean Expressions
de Morgan’s laws state a range of expressions which, when used in any boolean function, can be converted into an expression that uses only NAND or NOR functions.
Why?
This means that any circuit can be built from a single type of logic gate, which reduces manufacturing costs as only one type of gate can only be used. It is much easier to buy a single item in bulk rather than have several different components which must be manufactured independently, reducing costs for the manufacturer and ultimately the consumer.
Adders
Half adders
A half adder is a logic gate that takes two bit inputs and computes the addition result of them, as well as a carry.
To do this, the half adder uses A and B as inputs, with an XOR gate to get S (the Sum). Additionally, there is an AND gate which outputs C (Carry) if both A and B are True. Wires connect the output of the XOR gate to the input of the AND gate, so that the carry can be calculated. This carry can then subsequently be used in a full adder.
Full adders
A full adder is a logic gate that takes three bit inputs and computes the addition result of them, as well as a carry.
2.1 Elements of computational thinking
2.1.1 Thinking abstractly
Abstraction is the process of filtering unnecessary information from what is really needed to solve a problem - removing details to simplify the creation of something like an application.
Removing unncesessary detail, keeping only relevant information.,
Abstraction is present throughout day to day life. The London Underground map is a typical example of abstraction on a large scale, but this way of thinking can be applied to many situations. When driving a car, you do not need to know how the engine functions, the role of friction on tyres or the chemical composition of the metal shell of the vehicle. You just need to know how to use the steering wheel, brake/accelerate pedal and more, not how exactly these work. That would be the role of a mechanic.
Removing these unnecessary details allows programmers to focus on the core issue, rather than spending time on things not needed in a situation.
Abstraction significantly differs from reality. The London Underground map allows people to easily navigate the tube lines, without showing know the exact distance between stops or elevation changes, whilst retaining the spatial position and name of each stop. This allows people to focus on what is needed - getting from one stop to another.
You additionally need to know how to devise an abstract model for a situation. This is a theoretical model for how a system or program should function. For example, a flowchart just shows the logic and flow of a program. Likewise, an expression in code of “a = b + c” abstracts away the memory addresses, binary values, fetch-decode-execute cycle and more.
2.1.2 Thinking ahead
Identifying the preconditions, inputs, outputs and reusable components of a program.
To think ahead, the inputs and outputs of a given situation are needed. There may also be preconditions which should be determined before devising a solution to a problem.
Using the process of abstraction, the input to a computational problem is the information relevant to it, nothing else. Represented programatically, this would be the parameters passed to a function. The output of the computational problem is its solution, returned from a function.
In order to do this, the initial abstract model must be turned into a complete program, whislt being correct (accounting for all inputs) and also as efficient as possible.
Inputs and outputs should be identified in the documentation, or in code comments. For example the docstring of a subroutine may include “A list of integers intList = [1, 2, 3…]”. This shows programmers what must be inputted to the subroutine, and this process can also be continued with the outputs too, minimising ambiguity.
THinking ahead is also the anticipation of problems and issues. Also known as exceptions in code. In code, a statement could be added to check for an issue, for example returning early if a list does not contain any elements (if len(list) == 0). Alternatively, the responsibility can be left to the person to just not call something where an exception may be raised. This can be done by using preconditions, a statement dictating a condition that must be met, typically in order for code that requires this value to execute. Benefits of this include making components reusable - for example, through subroutines - and programmers will also know what conditions must be met to call a subroutine, reducing CPU overhead and execution times from unnecessary checks within the subroutines. This subsequently creates shorter, clearer, more efficient, reusable and cleaner code which improves maintenance and debugging.
Caching, the temporary storage of information, is an example of thinking ahead. This webpage may or may not be cached depending on how many people are using it. On the first load to this URL, my webserver serves it from storage (slow). The second time, it may be loaded from storage again (slow). The third time, the server knows it is frequently accessed, so it keeps a copy of it in cache storage (fast) and you can see the page load much more quickly.
You can see if this page along with other resources on iBaguette are cached by checking the HTTP Request Headers for
Cf-Cache-Status- if this isHITthen yes, it’s been cached. TheAgeheader also tells you for how long it has been in the cache!
On the client side, JavaScript and CSS stylesheets are cached by your browser as they typically remain constant for the duration of your visit to a certain domain. To free up memory, when you leave a website, the cached assets may be discarded as they are no longer needed.
This:
- provides faster access to resources in the cache, sub-millisecond vs server request which can take many seconds
- saves cost of bandwidth/server egress
- reduces load on backend webservers such as reducing database query times
- increases efficiency and productivity of users
However, the drawbacks are:
- being served a stale (old) copy of a website or server despite of an update being made
- takes up storage/memory, especially if large resources like images are cached
- incorrect or corrupt cached data will continue to be served to many people for a longer time
2.1.3 Thinking procedurally
Procedural decomposition means breaking a large problem into sub-problems, with each of these completing their own distinct, identifiable task. These sub-problems can be indefinitely divided into further sub-problems.
This thought process gives code a clear structure and improves code quality. As a result, the code is easier to understand and subsequently design.
- Modularisation involves breaking the overall problem down into subroutines.
- Each of these subroutines or other code segments follow sequence, selection and iteration statements
- Recursion is used to further optimise the efficiency of a program.
To do this, hierarchy charts are used. At the root (top) the overall problem is outlined with the first level below being an outline with what should occur to solve it. In an exam, most hierarchy chart scenarios will probably include initialising variables, the main process program (to be further decomposed) and the final output. There can be as many levels as are required to break down and decompose the overall task.,
2.1.4 Thinking logically
2.1.5 Thinking concurrently
Algorithms
A good algorithm has clear and precise steps that produce the correct output for any set of valid inputs.
They must also always terminate at one point, executing efficiently, using minimal resources in as little steps as possible.
It must also be designed in a clear manner, with it being easy to understand and easily modifiable by others.
Big-O notation
Big-O notation measures the time complexity of and resource a specific algorithm requires in order to complete.
The most “influential” or dominant term counts when deriving the Big-O of a specific algorithm.
The order of time complexity of differing Big-O can be:
Linear - O(n)
Logarithmic - O(logn)
Exponential - O(n2)
Factorial - O(n!)
Superexponential - O(nn)
Algorithms with an exponential time complexity or greater are hopelessly inefficient for large values of n, whereas logarithmic time complexities are extremely efficient for large numbers.
For logarithmic complexities, one extra computation step is required for a doubling of the numerical value
Where n = 1024, a log value requires 210 steps = 10 steps.
For n = 2048, the amount of steps is 11 - or 1 extra step. For other algorithms with linear complexity this will be an increase of 1024 steps.
Searching algorithms
Linear search
Linear search is a systematic way of searching for an element in a list,
Every element will be progressively searched through until the target item is found
The average number of elements searched is (len(list))/2. For the worst case, it will be len(list).
function linearSearch(namelist, name_to_find)
index = -1
i = 0
found = False
while i < length(namelist) AND NOT found
if namelist[i] == name_to_find then
index = i
found = True
endif
i = i + 1
endwhile
return index
endfunction
The number of steps is:
2 steps in innermost loop (loop makes a factor)
= 2n
plus 3 steps above the loop
= +3
= 2n+3
Big-O notation for linear search is O(n).
Can be perfomed on any list, sorted or unsorted.
Binary search
Divide and conquer!
Split the list length in half. (If it’s even, go for the lower one)
See if the number/alphabetical index/your search criteria is above/below, and remove the opposing side of the list.
Repeat until item is found.
Sorting algorithms
Depending on how many items and type of unsorted items there are in an unsorted array, there are different algorithms that perform better on different types of data,
Bubble sort
Is useful for a small amount of items.
Where there are n items, n-1 passes are made through the array.
Bubble sort works by comparing two adjacent items in an array and swapping them if the order does not match the required order.
This can involve moving one element to the complete other side of the array in one pass.
for i = 0 to n - 2
for j = 0 to (n – i - 2)
if a [j] > a[j + 1 then
temp = a[j]
a[j] = a[j + 1]
a[j + 1] = temp
endif
next j
next i
The algorithm works by repeatedly comparing adjacent elements in the array and swapping them if they are in the wrong order, repeating until the entire array is sorted.
Time complexity: O(n2)
Insertion sort
This sort starts at the start of an array and moves it by one until the correct position is found.
procedure insertionSort(aList)
for j = 1 to len(aList) - 1
nextItem = aList[j]
i = j – 1
while i >= 0 and aList[i] > nextItem
aList[i + 1] = aList[i]
i = i - 1
endwhile
aList[i + 1] = nextItem
next j
endprocedure
Time complexity: O(n2)
Though, it’s faster than bubble sort.
Merge sort

The merge sort involves repeatedly splitting unsorted array into n sublists.
The sublists are then merged to make a sorted list!
A list of length 16 will be split into 8x2, 4x4, 2x8 then 1x16 individual elements.
Afterwards, they are combined into 2x8 lists. Then, one half of the unsorted elements is compared to the corresponding other half of the unsorted elements.
For example index 1 of the leftmost half’s first list is compared to index 1 of the rightmost half’s first list and the smallest value is written.
When there are two lists remaining from either half of the overall list (so 8x2), this is repeated and the sorted list is written.
Big-O notation for this sorting algorithm is O(n log2n)
Quick sort
This uses a pivot value or split point, typically the first element, which divides the list into two sublists as part of the main list. One half will contain elements that are greater than those of the pivot point and the other will contain those less than the pivot value.
Alternatively the pivot value can be chosen from looking at the start, middle and end values.
Left and right pointers are used on either side of the array. If the pointer value compares two items that is due to be on the right/left of the split point, the two values at each pointers’ index value will be swapped.
Average time complexity is O(n log n)
Worst-case complexity is O(n2)
Graph traveral algorithms
Depth-first traversal
The DFT uses a stack and list to keep track of the name and nodes that have been visited.
The first value, A, is pushed to the stack and its immediate neighbor is added to the stack.
The stack is then popped.
If the stack has zero depth, values are popped until the next neighbour value is found.
Optimisation algorithms
Remember:
A vertex is a point on a graph with a value (such as A, B, C etc.)
An edge is a point on the graph that joins two (or more of) these vertices.
Dijkstra’s shortest path algorithm
Dijkstra’s shortest path algorithm is a simple algorithm that is designed to find the shortest path between a start node and every other node in a weighted graph. It is similar to a breadth-first search.
This algorithm uses the priority queue data structure in order to keep a record of the vertex next to visit.
To start, a temporary distance to each node is “calculated”. The start node is initialised to 0, and all other nodes initialised to infinity ∞.
Step 1
All nodes are added into the priority queue with the first being zero, all others ∞.
In the graph diagram, all nodes are white as they have not been visited.
Step 2
The fist node is “visited” and therefore coloured green. All other nodes that are connected to this node through an edge are coloured in light green.
The node is then dequeued (from the start of the queue) (and therefore removed from it).
The values of neighbouring nodes are then recalculated, assigning them the value of the shortest path to these nodes, and updated if a shorter path is found.
The priority queue structure moves the connected values to the start of the queue, with the next closest being moved to the front.
Step 3
The next node is dequeued, colouring it green.
Values of its neigbouring nodes are then coloured light green
All new unvisited neigbours’ values are then calculated.
Step 4
Repeat steps 2/3 until all nodes have been coloured in green (visited). The algorithm terminates when the target node is reached or there are no unknown nodes remaining.
The queue will be empty (priorityQueue.isEmpty() >>> True)
The graph displays the minimum distances from the original start node to each other node!
Question: In Dijkstra’s algorithm, what would the value in the priority queue be if the distance from previous traversal
A->Cto a node was calculatedB, but this node now is no longer connected through an edge to the current nodeC? (In this case,C:D= 2,C:E= 5). What would the value of this nodeBbe, when its distance was only calculated to the previous node (A:B= 10)?
Answer: The priority queue would store the value from the initial neighbouring calculation which would be 10.
If the value of this prior shortest node is the lowest, the algorithm would use the next largest element in the queue.
If there are no connected nodes, the algorithm would backtrack.
The A* Algorithm
This is not the same as the grade you’re going to be getting if you don’t understand this.
This algorithm is designed to find the fastest point from a start node to an end node.
2.2 Problem solving and programming
2.2.1 Programming techniques

Programming basics
An algorithm is a sequence of instructions that can be followed to solve a problem.
Pseudocode is a middleground between a functional programming language and English. There are no strict rules on how to write pseudocode. Instead, there are rough guidelines which differ slightly.
It’s not tied to a specific programming language, allowing people who may not know the same programming languages, or stakeholders who may not be technical enough to understand program code, to understand and follow the logic behind how a program should work. My mum could probably understand it.
Variables are memory locations with an identifier whose data can be overwritten. Their data contents are able to change during execution. This is compared to constants, which are only declared once during initial assignment. Changing the value of a constant would require recompilation.
Constants reduce the risk of accidental modification during runtime, making the code easier to understand too. There may be also more efficient compiled code, as the computer knows that a specific memory data location will not be changing whilst a program is executing. Changing the value of a constant at its declaration point affects all occurrences of that constant in the code, making maintenance more easily performed as, for example, tax rates would only have to be changed at one point, when they are declared, which is typically at the start of a source program.
Using the
constkeyword for tax rates is acceptable as for most practical purposes will not need to change.
An IDE (Integrated Development Environment) is software that makes the development and maintenance of code easier. Facilities offered by these include adding line numbers, automatically indenting code, auto-completing commands, commenting or uncommenting regions, syntax highlighting and debugging options, including breakpoint setting, variable watching, stepping through code and tracing.
Program flow
Progrramming languages and algorithms have a set of statements to determine in order that they reach a goal. There are three distinct flow structures which control this flow:
Sequencing
Order of code.
Iteration
For/do/while loops.
WHILE a CONDITION is NOT MET, then KEEP LOOPING until it is.
do… until
Statement will always be executed at least once - checks the boolean evaluation after the initial do statement.
Infinite loop
(As well as an Apple store in California)
Infinite loops can be caused by a logic error when programming, or be intentional, as seen in games or other sensory devices.
In games, an outer while True loop which encloses the entire game logic can be made to draw images on the screen after having calculated positions. Pauses can be added (time.sleep()) to prevent the game refreshing too fast for a monitor, ensuring smooth motion such as at 30fps. Frame rate limiting uses the same principle.
Sensors, like ones checking for a lanyard’s NFC chip to open/close school gates, can also have an outer while True loop which infinitely runs, ensuring that the sensor’s value is always being checked, so once an inner condition is met, the gates will open.
for… next
Also known as definite iteration. The segment of code will be repeated the specified/calculated number of times. The counter variable (or step value w/default of 1) is incremented each iteration of the loop.
next i
endwhile
Selection
If statements.
IF THIS, THEN do THAT. ELSE, go back to start.
Program flow is controlled by evaluating a Boolean condition, which is one that evaluates either to True or False. If it is true, the following statements are executed. If not, the (typically) indented code below will not run.
Elseif
An example of selection within pseudocode. this must be used in conjunction with many other selection statements, and the programming language will
Switch/case
Performs structural pattern matching rather than boolean evaluation.
(Also known as match/case in Python 3.10+!)
endswitch
Nested if… else
[TODO: The rest of this! Easy stuff]
Subroutines
Before starting this, it’s important to know the distinctions in terminology 👇👇👇
A subroutine is a general term used to refer to a named block of code that can be called from other parts of a program.
Functions are a type of subroutine that return a value to the caller. They are designed to perform a specific task, and provide a result.
Procedures are type of subroutine that does not return a value. They are a set of instructions for performing a specific task without returning a value - but this does not mean they do not change any code or create an output (e.g. print message)
Both functions and procedures are types of subroutines.
Subroutines perform a specific, frequently used set of instructions within a program.
Subroutines comprise functions and procedures.
Allows programs to become more modular
When a subroutine’s name is called, the program will halt execution from the current line, and skip to the line of the subroutine.
Functions
Return a value. Can be programmer defined or language built-in.
sqrt(number) is commonly used to return the square root of a passed in number
len(string) is commonly used to return the length of the passed in parameter
Library subroutines
“Log off, see ya later. Go to the library”
Must be imported to be used.
import random # this is the library (subroutine)
print(random.randint(1,10)) # subroutine (funtion) here is `randint` which returns a # from 1 to 10.
Params and args
Parameters are placeholder values which are only alongside their subroutines during definition - they don’t change.
Arguments are the specific values passed into the subroutine. Depending on what is called, they can change.
When an argument is passed into the subroutine, the name, type (in most cases), length etc. don’t matter - just the order in which they are passed in. Multiple parameters can be defined, typically separated by commas, and their relative position denotes the value the argument will take within the subroutine.
In Python, for example, arguments are passed by value. The value of the statement is copied into the parameter. This means that the original is not modified - the code within the subroutine will not change the original value that was passed in.
Other programming languages can pass arguments by reference. This means that the actual memory address and the contents are passed into the called subroutine
Passing by value
import random
peas_count = 10
def open_pea_pod(peas_count):
print("Start of subroutine peas:", peas_count)
peas_in_pod = random.randint(3, 10)
print(f"Adding {peas_in_pod} peas")
peas_count = peas_count + peas_in_pod
print("New peas count:", peas_count)
print("Before opening the pod:", peas_count)
open_pea_pod(count_peas)
print("After opening the pod:", peas_count)
# Output
>>> Before opening the pod: 10
>>> Start of subroutine peas: 10
>>> Adding 9 peas
>>> New peas count: 19
>>> After opening the pod: 10
Procedures are an example of… procedural programming.
Recursion
Recursion is when a function calls itself. In order that this is handled well, there must be an end condition, where the function will not be recalled.
It can be more intuitive for a function to call itself to compute an output, than having to modify and adapt the function to use an iterative approach (loop).
When a function calls itself, the caller pauses execution, and the function call is continued instead. All subcalls are independent - they are considered as separate functions of the program. The return value of functions are added (pushed) onto a stack, until a base condition is met where recursion no longer occurs (usually a SELECTION statement), and the function stack “unwinds”, and each subcall’s return value is passed into the value of what the caller wanted. Each call results in an increasing amount of data being processed. A consequence of this is high memory usage, as each function call copies (typically by value) variables and parameters, and the function code itself, into a new memory address. This can lead to a stack overflow error, when a call would increase memory usage above the stack’s limit.
This is opposed to an iterative approach, which executes the same instructions for each pass.
There must be a base/stopping condition, and finite number of calls whilst this base condition is not met.
Factorials
A factorial of a number is the number multiplied by all numbers between it (inclusive) and 0. If you’re looking for the factorial of 5, then you would do 5 . This is denoted as
procedure calc(n)
if n == 0 then
factorial = 1
else
// Call itself - value is not fully factorialised to 0
factorial = n * calc(n – 1)
endif
print(factorial)
endprocedure
Fibbonaci sequencing
function fib(n)
if n <= 1 then
return n
else
return fib(n-1) + fib(n-2)
endif
endfunction
OOP
Classes are a blueprint for an object. They define what each object that inherits that class should look like/have (its properties) as well as what it can do - its methods.
Attributes (properties) of a class Cat may be colour, size, breed.
Methods (procedures) that this Cat class can perform include meow, purr, walk…
Encapsulation
Encapsulation is when data is bundled (encapsulated) together to reduce the code complexity and superfluous code. This is done by creating classes. Once the object is instantiated, public methods can be effectively ignored and private attributes hidden from users so that they cannot be changed without intent.
Attributes and methods in the class definition are wrapped (encapsulated) in the class definiton. For example if you have a list1 variable and you want to sort it, you do list1.sort() - for every list that is created, the programming language defines a sort method.
Public and private
Generally, procedures are public - it is a common method for each object that uses that class as its blueprint.
Attributes are normally declared as private, so that they cannot be changed, except for when executing a procedure.
Instantiation
Instantiation is creating an instance of an object. An object is instantated when it is being created from a class.
myCat = new Cat("Tiga")
Setters and getters
When an object which inherits from a class is defined, the attributes of this object cannot be directly accessed or modified - this is the OOP principal of data hiding. Instead, public procedures which get or set a value are used instead.
Instead within the class, more public procedures can be added that setAnAttribute or getAnAttribute. The set procedure will take a parameter, and the get procedure will return the value of the attribute.
2.2.2 Computational methods

TEMP SECTION: Data Structures
Arrays, records and tuples
A variable is a location in memory which holds a particular variable, which can be of a specific type.
Strings, for example, may require more memory to hold their values, as opposed to Booleans which are either True or False.
Elementary data types include chars, reals, integers, booleans.
Structured data types, depending on the programming language, may be built-in to the syntax. These will include list of records, lists, arrays and strings. Structured data types are typically decomposed into elementary data types.
Arrays
Arrays, like all data structures, must be declared. During declaration, its size (length) and stored data types must be stated. This is to ensure that there are enough contiguous memory locations for the data to be stored.
Arrays are therefore static (cannot grow or shrink in length). However, elements within the array can be changed after initialisation (during runtime), making them mutable data structures. They can also only store one data type.
// Example in Pseudocode:
ARRAY words[4]
words = ["hi", "my", "name", "is", "Joe"]
Note: For the purposes of simplicity, it is best to ignore Python’s (and other languages’) implementations of arrays, as they can be dynamic.
Arrays can also have multiple dimensions. These can be denoted by:
ARRAY words[2, 4, 7]
This is a 3D array with a length of 2, height of 4, and width of 7. With zero-index languages, this is a total of 358 = 120 different positions.
These can be accessed by accessing the array name followed by the row and column indexes. E.g. words[1, 3] would return the value at row index 1 and column index 3.
Trace tables [tbd]
When tracing the results of a function, trace tables can be used. The table is named the same as the array. For each new declaration
Lists
Lists, like arrays, are mutable structures. However, unlike arrays, their length does not need to be declared during initialisation as they are dynamic structures; they can also store any types of data inside.
// Example in Pseudocode:
LIST sentence[4]
sentence = ["Hi", "i", "am", 8]
sentence.append("!")
sentence.insert(4, ["years", "old"])
print(sentence[4][1])
>>> old
Tuples
Tuples are a mixture of arrays and lists.
Tuples are lists which cannot be modified at runtime - they are immutable. Their length also therefore cannot change, making them static too. However, despite these drawbacks, they too can store more than one data type. They must also be an ordered set of values.
// Example in Pseudocode:
TUPLE words[4]
words = ("Hi", "i", "am", "8")
words.append("!")
// Syntax error: cannot append to tuple at runtime
This may be a bad idea to implement if the end user needs to update their name for example.
Records
Records are like a spreadsheet of data, and similarly are used to store data permanently. Records exhibit the characteristics of a tuple.
Queues
Queues are FIFO specialist data structures and are categorised as an abstract data type, alongside stacks (and lists in some languages).
What is an abstract data type?
An abstract data type is one that is implemented by the programmer, rather than one being defined in the programming language itself. They are descriptions of how data can be viewed and operations that can be performed on it, but not how it itself is constructed. The implementation of ADTs are hidden from the user.
Static queues
Queues are often used in event-driven programming, with graphical user interfaces as an example. There must be an event loop which continually checks for new events, which are then added to the event queue. This makes them essential for asynchronous programming.
A queue exhibits the same traits of a list, but data can only be inserted one way (pushing/enqueuing) and retrieved (popping/dequeued) from the other end - think of a pipe, or a list of printer jobs.
Queue operations
There are four main operations which queues can process:
- Enqueuing (pushing) an item - this adds it to the end of the queue
queue.enqueue(item)
- Dequeuing (popping) and item - this removes it from the front of the queue.
queue.dequeue(item)
As queues are First In, First Out structures, the items added last will be the last to be processed, and all other items in front of it will be processed beforehand
- Checking full state
queue.isFull()
- Checking empty state
queue.isEmpty()
Items cannot be inserted to a specific position within a queue data structure.
During initialisation, due the static nature of queues, their maxSize must be specified during initialisation. Pseudocode can be written to keep track of the currentSize and compare this with the maxSize to disallow adding items to a full queue or removing items from a queue with zero depth.
Circular Queues
When an item is dequeued from a static queue, the space it occupied in memory cannot be reused, which is wasteful. Likewise, moving all elements of this array up by one in order to free memory at the end of the queue would be wasteful and CPU cycle heavy.
Queues can alternatively be completely circular and use pointers to denote the start and end index instead. These are implemented as arrays (static).
When items are popped from circular queues, the start pointer simply moves to the next item along (items are dequeued from the start). When this occurs, another element can pushed into this array as there is a memory location available and the end pointer now moves to this most recently pushed element, whilst the start pointer is incremented to the next element. This means that free spaces can continually be reused
Priority Queues
Ever been on a Ryanair flight and the people with Priority queue get in and hog the seats first? The same principal applies here. Each element in the queue has a priority associated with it, which can be denoted by having a number or letter when enqueuing. (pqueue.enQueue("timothy", A)). This is beneficial for giving preference to essential items, but does require more processing overhead to maintain.
Lists
Lists are another abstract data type. As briefly touched upon earlier, different languages have varying support for the type of list which is implemented. Python, VB and Java all have built-in dynamic lists, whereas the C family have static lists
Dynamic lists
When dynamic lists are being used, the memory heap is accessed. A freely available memory space is obtained from the heap, and a value is added to it. If it is deleted, the memory location is returned to the heap. Pointers are used to traverse to the next index in the list when being traversed.
The heap is a dynamic section of memory designed to hold data during runtime, and release it when it is no longer required by the program.
Some languages do not contain the ability to use a listas a data structure, and arrays must be used instead. As arrays are always static, the length must be specified during initialisation, which is something that may not always be known.
A few pseudocode procedures and functions are available:
list.isEmpty()-> boolean; tests for empty listisFull()is not needed; lists are dynamically sized
list.append(item)-> Nonelist.remove(item)-> Nonelist.count(item)-> intlist.index(item)-> intlist.append(item)-> Nonelist.index(position, item)-> intlist.pop()-> valuelist.append(position)-> Nonelen(list)-> int
Linked lists
Each element (node) of a linked list contains two items: the data item and the next address, or link, item. Several of these nodes linked together are known as a linked list. Linked lists are dynamic lists toom as the link item points to the memory address of the next item in the array, if there is one. The memory locations of these linked lists are non-contiguous; the link field can point to any available memory space. When implemented by the programming language, the first node’s memory location is kept track of.
When deleting data, the pointer to the node to be deleted would change to the position of the node after the deleted node. (This is because the link field of the preceding node would be pointing to the deleted node, and not the node after it.)
When inserting data, the preceding node’s link is modified to point to a free memory location to be used as a node, then assigning this location with a value, then adding the link item to the next node.
Linked lists can also store multiple link fields if necessary. One link may be the position of following nodes based on their data in alphabetical order, whilst others may be in another order. This is known as a multilinked list.
Stacks
Stacks are LIFO (last in, first out) abstract data structures. This means that the most recent item added will also be the first one removed when processed.
The undo button or web browser history can be an example of a stack. This is because as changes are made to the document, the most recent version is on the top - it is building on the previous revisions. When you Ctrl + Z, the most recent change is removed (popped) - if that makes sense?
Another way to view a stack is by having a tower of books in a library. If somebody wants to return a book, this is placed on top of the other books. When these books need to be put back on the shelves, the book on top will be processed first.
This can be described as: the order of insertion is the reverse of the order of removal.
stack.push(item) - adds item to stack top
stack.pop() - removes and returns the top item
stack.isEmpty() - checks if stack is empty (depth of 0)
stack.isFull() - checks if stack is full
stack.peek() - returns top without removal
stack.size() - number of items
items = ["a", "b", "c", "d", "e"]
stack = []
new_items = []
element = 0
for letter in items:
stack.push(letter)
for item in stack:
value = stack.pop()
new_items.append(value)
print(stack)
if new_items[::-1] == stack:
print("Stacked successful!")
Attempting to push to a full stack will result in an overflow error. “Stack Overflow”: ran out of memory
Likewise, popping an empty stack will give an underflow error.
Call stack
The call stack is a system-level stack that is used to store current information about executing functions and subroutines. High-level languages can abstract the details of the call stack from programmers. It allows for parameters to be used and the results of functions in their returns to be passed. This is especailly useful if there are a range of functions being used at once, or recursion is in use.
Recursion involves the return data of one function being used to complete the output of another function. These functions may also call other functions if this is necessary for an output too.
The last (most recent) function to be called will be computed first. Then, when a value is returned, this is placed on the call stack as the output to the function that called for this value. And this is repeated.
- Stack space is allocated for local variables
- Parameters are saved onto the stack
- The address to the return function is saved to the stack
- Execution is transferred to the function code
- Function is executed
- The return address is retrieved
- Parameters are popped
- Execution is transferred back to the return function
Hash tables
Hash tables, an abstract data structure, involves processing the value of an item with a hashing function to assert its address. No matter how large the dataset, these will be fast, as there is no searching algorithm being used; only one calculation is needed to find the address of the item (provided the hash function is good, and there are no collisions - see below).
address = key mod (#ofslots) - this is the hash function
The remainder of this function will be the address at which to insert the data.
However, collisions may occur when inserting data. The same address can be generated if, for example, the length of the data is 100, and 153 and 253 are being processed.
Collisions can be resolved by using the next available free space in the hash table, by incrementing the address by one until a free memory location is found.
However, there are disadvantages to this. There may be “clustering” of data in a certain area of the table, or, if a bad skipping algorithm is used, there may be infinitely unable to store data if the skip length is 2, and there no free slot at 1, 3, 5, 7, 9 etc. When searching for data, all collisions must be checked, which is (understandably) time, memory and CPU cycle heavy.
A 2D hash table can be used to fix this to an extent, by using the first hash function to determine the index of the 2D array, and then appending the data to the end of the array at that index. This is known as chaining, which uses a linked list to store data at the same index. This is a good solution for when there are a lot of collisions, but can be slow to process - although this is still faster than searching the main array for the data.
Credits + Footnotes
[1] Andy aka (https://electronics.stackexchange.com/users/20218/andy-aka), Difference between a bus and a wire, URL (version: 2014-01-11): https://electronics.stackexchange.com/q/96149
[2] Teach-ICT A Level Computing - ALU. [online] Available here [Accessed 22 May 2023].
[3] Yes I know it should be GPUs for parallel processing but you can still do it on your CPU if you really want to
Une lumière dorée brille sans fin tout au bout du chemin
Written with StackEdit :)